|
4) Distributed, heterogeneous data access
|
|
d) Database
Federation
Level
|
|
| |
| 1) Storage and retrieval of
Very large datasets |
2) Access optimization of
distributed data |
3) Data mining and discovery
of access patterns |
|
c) Dataset
Level |
|
b) File
Level |
a) Storage
Level |
|
5) Agent Technology
|
|
|
|
Scientific
Data Management
Integrated Software Infrastructure Center
Center
Director:
Arie
Shoshani
National Energy Research Scientific Computing Division
Lawrence Berkeley National Laboratory
Mail Stop 50B-3238
Berkeley, CA 94720
Tel: (510) 486-5171
Fax: (510) 486-4004
Email: [email protected]
Principal
Investigators by site
DOE
Laboratories:
Universities:
Table
of Contents
Abstract
Terascale
computing and large scientific experiments produce enormous quantities of data
that require effective and efficient management. The task of managing
scientific data is so overwhelming that scientists spend much of their time
managing the data by developing special purpose solutions, rather than using
their time effectively for scientific investigation and discovery. The goal of
this proposal is to establish an Enabling Technology Center that will provide
a coordinated framework for the unification, development, deployment, and
reuse of scientific data management software.
We
have assembled a team of experts who work in the scientific data management
domain with application scientists in areas critical to the DOE mission. The
team has identified four main areas that are essential to scientific data
management, emphasizing efficient management and data mining of very large,
heterogeneous, distributed datasets. In
addition, we have identified technologies that fall into four tier levels:
storage, file, dataset, and dataset federation.
This area and tier framework is the basis for a management
structure that will ensure the vertical integration of technologies in each
area over these tier levels, as well as cross utilization of area
technologies. The results
expected are efficient, well-integrated, robust scientific data management
software modules that will provide end-to-end solutions to multiple scientific
applications. In the short term,
we expect to enhance the robustness of previously developed technologies and
deploy then to specific scientific applications.
In the longer term, we will conduct research and development based on
an iterative experience cycle with the deployment of our technology.
Back
to the table of contents
1.
Goals
and Scope
Challenge: Terascale scientific computations generate very
large quantities of data that needs to be well managed in order to facilitate
scientific analysis and discovery. The
amount of generated and derived data products are typically measured in
hundreds of terabytes, or even petabytes, a daunting challenge for a
scientific researcher to manage. Several of the teams involved in this
proposal have developed procedures, tools and methods addressing individual
aspects of scientific data management and data mining for individual
application areas. However, there has been no attempt to unify and coordinate
these efforts across all the data management technologies relevant to DOE
mission and across all the SciDAC scientific applications.
Objective: We propose to establish an advanced Scientific
Data Management (SDM) Enabling Technology Center (ETC) that will effectively
serve a broad energy research community by successfully addressing their data
management needs. The objective of this center is to provide application
scientists with a suite of efficient, well integrated, easy to use tools and
techniques that allows them to concentrate on their research by minimizing the
effort they must spend managing their data.
Mission:
To achieve this objective, the SDM Center must:
-
Develop and
deploy an organizational framework that integrates scientific data
management technology into a set of robust, user-friendly, and end-to-end
software tools to support DOE scientific application requirements.
These tools will provide for effective and efficient moving, storing,
querying, retrieving, and mining of multi-petabyte scientific data sets.
This set of tools will be made available to the broad energy research
community.
-
Create an
application-driven data management research and development pipeline in
which the long-term-needs of the applications will be met by developing proof-of-concept
research prototypes and then hardening and integrating them into the
end-to-end SDM Center framework. Science needs will drive the computer
science work at SDM Center, which will provide experienced teams and the
best data management tools and facilities to meet scientific application
goals. This strategy has been used to build a multi-institution,
multi-disciplinary SDM-ETC team with the unique combination of skills,
experience, tools, and facilities that are necessary to successfully realize
the full potential of terascale computers for scientific discovery. (DOEs
Office of Science Report on Scientific Discovery through Advanced
Computing, March 24, 2000).
-
Work
synergistically with DOE scientific application teams and SciDAC
Collaboratory Pilot teams by addressing the most critical issues in a timely
and comprehensive fashion in order to better serve a broader DOE community.
-
Educate
and train the next generation of interdisciplinary students, scientists, and
educators, who will be schooled in the ability to conceptualize, design, and
implement state-of-the-art scientific data management technologies, in order
to achieve the dream of specific scientific application functionalities.
Specific
scientific application areas initially targeted to utilize the SDM Center
framework include climate simulation and model development, computational
biology, high energy and nuclear physics, and astrophysics. These application
areas are of particular DOE interest and are being extensively pursued at ANL,
LBNL, LLNL, and ORNL. Most of the research teams involved in this project have
established long-term working relationships with application scientists in these
areas (see the attached letters of support from Anthony Mezzacappa
Astrophysics, Douglas Olson High Energy Physics, Tom Slezak
Bioinformatics, Benjamin Santer Climate Modeling, as well as storage system
vendors IBM, GENROCO, and StorageTek.)
Strategy: Our
strategy consists of 3 aspects: 1) work closely with specific application areas;
2) develop software products in a pipeline fashion; and 3) set up a framework
for verification and validation of software products.
Specifically, the SDM Center strategy is to initially associate each component tool with
one or two targeted application areas. By
doing so, we can apply a focused effort and demonstrate the utility of each SDM
tool. This is worthwhile in its own right, since applying an SDM tool in
multiple sites or experiments for a single application area is a challenging
task. We will use this experience
to identify and target additional application areas for use of the SDM tools in
the out years of the Center. In
other words, our strategy is to improve and integrate existing technology and
deploy them in the targeted scientific application area. Concurrently, and in cooperation with application scientists,
we will identify areas that are missing or need to be developed further.
We will start research and development activities on these newly
identified needs, thus fulfilling our pipeline strategy. To insure a
timely transition of research codes into robust production codes, we plan
to use well-tested techniques of verification and validation of software
products (see the section on Software Process and Risk Management for a
detailed plan).
Science driven bottlenecks: Recent advances in scientific
data management and scientific data mining have made it possible to manage and
analyze massive amounts of simulated/collected data (terabytes) to facilitate
scientific analysis and discovery. Still many barriers exist that force
application scientists to spend an increasing amount of their time performing
basic data management tasks instead of pursuing their research. Major
bottlenecks inherent to most of our targeted scientific application areas
include:
-
Current I/O
techniques are too slow to provide a desirable data access rate. Accessing
the data in the fastest possible manner is crucial for many scientific
activities, especially real-time scientific visualization, required by such
application areas as astrophysics (different forms), cosmology, and
computational fluid dynamics.
-
Retrieving
data subsets of interest from storage systems (especially tertiary storage
systems) is a major bottleneck in analyzing the simulated/collected data.
This is a crucial step for scientific discovery in high energy and nuclear
physics as well as climate modeling and other earth science investigations.
-
Navigating
between heterogeneous, distributed data sources (e.g., Internet) and
transferring data between various interfaces is a pain-staking, largely
manual, and time-consuming process. The increasing number of these data
sources, especially in the computational biology community, is creating a
crisis.
-
Network
bandwidth continues to be a major bottleneck in transferring very large
datasets, especially across WAN. The migration of massive (terabytes)
datasets to the standard archives, such as PCMDI in global climate research
community, is an essential part of the collaborative research process.
However, often only a subset of the data is required at the
destination so minimizing the amount of data transferred over WANs will
continue to be an important need for the foreseeable future.
-
Existing
data management and data mining techniques do not scale up to petabytes of
scientific data sets, a typical size of data produced by simulations on
terascale computers.
To
overcome these bottlenecks is an emerging need of application scientists. To
address these needs, we have identified our first-priority goals. The
following section provides a concise description of these tasks and their ties
to application needs.
Technical Scope:
To
overcome Bottleneck #1: Build a set of
robust and fault tolerant tools, integrated into an SDM framework, that
optimize access to distributed scientific data sets. Depending on the
application constraints, massive scientific data sets are typically
distributed across multiple files on the secondary storage (disks) of
clusters, multiple tapes of tertiary storage, or across wide area network
(computational grids). Different types of data storage systems require
different strategies access optimization:
-
To overcome
I/O bottlenecks in cluster systems, our strategy is to let various hints, or
additional information about intended access or intended use of data,
determine physical data layout on disk, thus optimizing subsequent access to
these data. The types of hints that might be useful include but are not
limited to quality of service (QOS), intended use (scratch vs. persistent
file), or typical application access pattern (row-wise, column-wise, or
sub-blocks of data across a number of dimensions). The integration of such
hints will be performed at both the Parallel Virtual File System (PVFS)
layer (task 1a.ii) and the MPI-IO layer (task 1b.i). The latter will allow
applications to easily adapt their own hints. Results of application access
pattern analysis (task 3c.ii) will be one of the test-bed hints in
this area. If no hints are available, the data layout can be driven by the
results of clustering of similar data objects based on application specific
similarity measure (task 3c.i).
-
To optimize
shared access to tertiary storage (task 1c.i), improving the retrieval of subsets of
data that are spread over many files and multiple tapes is essential
(Bottleneck #2). These chunks of data are typically the result of matches to
partial range queries in HENP. By using a shared front end disk and
managing its content to maximize the sharing of files by users we can
minimize repeated files access from robotic tape systems.
A prototype system that uses this technology has been deployed at BNL
[STACS].
-
To optimize
access in distributed systems two strategies will be pursued. The first is to
copy replicas of the data from a remote archive into a local disk cache. A
number of issues, such as application driven cache replacement policies,
need to be investigated and developed as pluggable policy modules (task
3a.i) to implement this strategy. The second strategy is to provide an ROMIO
interface with grid technologies (task 2b.i) to bridge the gap between
traditional methods of file access and the ones provided by grid I/O
facilities (e.g., gridFTP).
To
overcome Bottleneck #2: Improve
retrieving chunks of data distributed across multiple files and/or multiple
storage media. We will create a robust and comprehensive software package
on top of STAR that integrates various high-dimensional indexing schemes to
deal with various forms of high-dimensional data (task 2c.i). Our strategy is
to use bitmap-based indexing schemes because their compression rates are very
high and, more importantly, efficient bitwise logical operations (equivalent
to boolean queries in search engines) can be performed without decompression
overheads. Thus, efficiency will be achieved in terms of both reduction of
space required and increase of the speed of the query handling (search and
retrieval). Results of dimension reduction methods (task 3b.i) and
multi-dimensional cluster analysis (task 3c.i) will make this effort more
effective and tractable .
To
overcome Bottleneck #3: Facilitate
navigation and exploration of heterogeneous and distributed data sources by
addressing the problems of data access and semantic integration. A
software component that addresses these daunting problems will be delivered as
part of the SDM Center framework. This component will include:
To
ensure the applicability of this package in dynamic, complex, real-world
environments, such as genomics, our strategy is to develop an automated,
meta-data based framework in which wrappers are created directly from
interface specific meta-data and linked in to the query engine. In
collaboration with Tom Slezak, our primary contact with the LLNL biology
directorate, we will identify, describe, and wrap several complex, web-based
data sources of interest to local geneticists. For the most important of these
sources, the wrappers will be used to semantically integrate the sources into
the query engine; the remainder will only be available through specialized
queries that do not require full integration.
To
overcome Bottleneck #4: Overcome network
bandwidth bottlenecks by optimizing data transfer rates and minimizing the
amount of data transferred. We will accomplish this by focusing on two
major activities:
-
The first
activity (task 1a.i) seeks to implement
more effective high-bandwidth transfers of very large datasets by: (1)
optimizing blocksizes and equipment configuration to improve transfer rates
and (2) implementing a reliable UDP service with capabilities to recover
from dropped packets, (3) testing a beta version of the AIX operating system
with improved TCP/IP performance over lossy networks, and (4) investigating
new data transfer protocols, such as Scheduled Transfer.
-
The second
activity primarily aims to minimize
the amount of data that needs to be transferred and stored.
An adaptable software package, ASPECT (task 3c.i), built on top of
HARNESS and VIPAR will be integrated into the SDM Center framework. Its main
purpose is to let simulation scientists plug-in a data analysis component of
their preference into the ASPECTs job monitoring and decision-making
framework. Having such a dynamic first-look analysis capability over
distributed data files will allow scientists to identify which data should
be migrated to standard archives, stored on a site storage system, or
deleted. Dimension reduction techniques (task 3b.i) will be integrated into
ASPECT to increase the efficiency and effectiveness of data analysis
techniques (e.g., cluster analysis) as well as to identify important
attributes that need to be stored or transferred.
To
overcome Bottleneck 5: Use agent
technology and our unique development testbed to provide demonstrable
scalability. Probe sites at ORNL and NERSC (task 1a.i), with their
state-of-the-art equipment and facilities, will be our place to be for
initial development and prototyping of the research activities of the SDM
Center. The expanded ORMAC agent
framework (task 5) will be our glue to ensure integration and
interoperation between various components developed within the Center as well
as between other components developed by SciDAC Collaboratory Pilot teams. We
believe that our advances in each area identified above, coupled with agent
technology as a means of integration, will provide data management solutions
scalable to multi-petabyte scientific data sets.
Back
to the table of contents
2.
Approach
Our
approach is to develop and deploy an organizational
framework that provides a path to integrate scientific data management
technology relevant to the DOE mission into a robust software toolkit.
In this framework, individual components with clear interfaces,
developed by several laboratories and universities, can be applied to multiple
application areas. Our framework was developed by selecting technical thrust
areas that are needed to support scientific data management and by
partitioning each thrust area into tiers based on the level of data
abstraction used. The four thrust
areas are:
-
Storage
and retrieval of very large datasets
-
Access
optimization of distributed data
-
Data
mining and discovery of access patterns
-
Access to
distributed, heterogeneous data
Four
tier levels are (based on the level of data abstraction):
-
The storage
level: refers to the way each file is stored in and accessed from physical
storage
-
The file
level: refers to the placement of files in disk or tape resources
-
The dataset
level: refers to optimization strategies that span all the files in the
dataset
-
The dataset
federation level: refers to access of multiple, heterogeneous, distributed
datasets
For
each thrust area and tier level, we identified one or more laboratories that
have already developed and/or deployed relevant software components.
We further identified and approached universities that have a strong
track record in these areas. Our
approach is designed to bring to fruition these technologies by enhancing,
packaging, integrating, and using them as components for multiple scientific
applications. In order to ensure vertical
integration in each of the thrust area, we identified area leaders
that will coordinate meeting and integration in their respective areas.
A summary of the organization of the components of the center is shown in
Figure 1. As can be seen, the
work at the dataset federation level relies on all aspects of the dataset
level below it. The modules at
the dataset, file, and storage levels are organized according to their
technical thrust. In addition, Agent technology will be used to provide enabling
communication among the various components.
Back
to the table of contents
3. Scientific
applications: typical scenarios and requirements
Because
the primary goal of the Center is to enable scientists to do better research,
an understanding of their data management requirements is essential. This
section provides a high-level overview of some of the problems being
encountered by scientists in several different application areas. These
applications form our initial focus areas, and were selected because of their
importance to the DOE scientific program and their familiarity to the computer
scientists involved in this proposal. As will be seen, the following examples
provided the basis for the "science-driven bottlenecks" described
above and are based on a deep understanding of the needs of these application
areas that came from years of experience working with the application
scientists.
Back
to the table of contents
3.1
Climate Modeling
Simulation
results from climate modeling are increasingly being measured in terabytes.
This data is only expected to increase as more ambitious models are simulated
with finer resolution, better physics, and a more accurate representation of
the land/ocean boundaries. For example, the Coupled Model Inter-comparison
Project (CMIP) that was established in 1995, collects yearly means for most of
the climate variables, and monthly means for only three of them (surface air
temperature, precipitation, and sea level pressure). This data is typically in
the order of 1-2 Gigabytes. In contrast, the more recent Atmospheric Model
Intercomparison Project (AMIP) II effort includes the monthly means for more
variables and is much larger, being measured in terabytes. Despite the fact
that AMIP II is more advanced than AMIP I, the organizers of AMIP II have
stated that among other limitations, "
. practical considerations have
resulted in some compromises based on:
1) the need for more fields to allow for more extensive analysis and
intercomparison;
2) data management limitations." (http://www-pcmdi.llnl.gov/amip/NEWS/amipnl8.html#TOC)
In
addition to the difficulties of dealing with large volumes of data, the Global
Climate Modeling community includes researchers who are very dispersed across
multiple national laboratories, centers (NCAR and PCMDI), topical centers (at
ORNL), and universities. This
generates many barriers in the development, application, and sharing of their
research that have not been adequately addressed. The most urgent needs
include:
-
Efficient
storage and retrieval of terabyte-scale datasets.
-
Support for
efficient transferring of those data to a centralized warehouse for
archiving and indexing.
-
Dynamic quick
and dirty data mining mechanisms for:
a) Monitoring and steering climate simulations that sometimes run for weeks
or months.
b)Filtering runs to choose between storing centrally or keeping locally.
-
Efficient
distributed pattern query, search, and retrieval mechanisms for comparing
simulations.
-
Transparent
parallel I/O mechanisms. Simulation outputs are often stored in multiple
files for post processing but analysis tools do not support parallel
reading.
-
Federated
database framework, with a transparent and monolithic view of archives,
possibly eliminating the need to centralize data.
All
these needs are addressed in this proposal.
Specifically, we address: efficient
storage, retrieval and transfer of terabyte-scale datasets, efficient
tertiary-storage access, data mining from large datasets, analysis of query
patterns, parallel I/O, and federated databases.
Back
to the table of contents
3.2
Astrophysics
An
unsolved problem in the astrophysics community is to understand the mechanisms
behind core-collapse supernova. Currently, the best simulation models that
address this problem rely on solving the Boltzman equation to determine the
concentration of gas molecules during the explosion. Terabytes of data result
from solving this equation in one dimension. The goal of future research is to
solve the 2-dimension Boltzman equation and to approximate the 3-dimension
Boltzman equation. A typical simulation run will involve modeling two aspects
of the core collapse, a hydrodynamic model and a transport model. The area
modeled is typically a 512x512x512 area for 1000 time units. The resulting
data for the hydrodynamic portion of the model will produce approximately 1 GB
per frame, resulting in a total of 1 TB of data for the entire time span. The
transport model is a 6-dimension model that results in 42 GB per frame, or 42
TB over 1000 time units.
In
this and similar applications, such as cosmology and CFD, data is generated
every N cycles for different variables. For subsequent analysis and
visualization, the data needs to be accessed in different forms along various
dimensions, producing varied access patterns. This places tremendous demands
on the data management and I/O systems. Effective solutions for speeding I/O
will help the applications that make heavy use of visualization.
In
this proposal we address various techniques to speed up I/O.
We will develop techniques for passing hints to the I/O system to aid
more robust and efficient analysis. We
will create metadata for use in efficient access to the data. And we will
create metadata allowing the underlying system to restructure the data for
future retrievals.
Back
to the table of contents
3.3 Genomics and proteomics
In
the genomics community, several dozen large, community data sources provide a
wealth of information on a specific sub-domain (e.g. human protein sequence,
human protein structure, mouse DNA). In addition, several hundred smaller data
sources provide highly specialized information, in many cases limited to data
produced by a specific lab. While some of the information contained in these
sites is duplicated in the community data sources, there is usually additional
information unique to that source.
Because
each source uses its own data format and custom interface, navigating between
sources and transferring data between interfaces is usually more complicated
than a simple mouse click or cut and paste operation.
For example, a protein sequence may be represented in three-character
code in one source, while another source expects it in one-character format.
These translations are not necessarily difficult, but they are time-consuming
when repeatedly applied. To help move between sites, some sources provide
cross-references to related data located elsewhere. While this is a big step
in helping identify related data, as implemented, it is far from the perfect
solution. In particular, these cross-references are not consistent across
databases. For example, PDB (a protein structure database) and SWISS-PROT (a
protein sequence database) contain cross-references. However, a PDB entry may
reference a SWISS-PROT entry that does not reference it, but may instead
reference other PDB entries. These
consistency violations mean that (1) these cross-references may be treated as
hints but should not be taken as definitive and (2) these links are uni-directional
instead of the expected bi-directional associations.
The
large number of sources, and the difficulty moving between them, is creating a
crisis. The situation is made worse by technological advances that allow data
to be created from the wet-lab at an ever-increasing rate, and the growing
need to combine these data in new and interesting ways. Information
such as homologs, annotations, structures, maps, locations, species
similarities, and much more must be analyzed before understanding the
impact each gene has on the overall organism. Such research, often referred to
as functional genomics or proteomics, is becoming the focal point of most
genomics and pharmaceutical efforts. Unfortunately, the data required to
perform this research is spread among dozens of sources.
The
Center is addressing problem of accessing data from multiple, heterogeneous
data sources by combining technology developed at three of the member
institutions into a cohesive, end-to-end solution.
Back
to the table of contents
3.4 High Energy and Nuclear Physics (HENP)
HENP
experiments consist of accelerating sub-atomic particles to nearly the speed
of light and forcing their collision. Each such collision (called an event)
produces a shower of additional particles and generates 1-10 megabytes of raw
data. The rate of data
collection in the STAR collaboration is a few events per second producing
about 10 megabytes/second on the average.
This corresponds to 107-108 events/year and a
data volume of about 300 terabytes/year. A typical experiment may run for 3
years.
In
the reconstruction phase each event is analyzed and summary properties
such as momentum, the number of particles of each type and the total energy of
the event are generated. The number of summary elements extracted per event is
typically quite large (100-200). The
volume of reconstruction data ranges from 30 to 600 terabytes/year.
Both raw and reconstructed data are saved.
During
analysis, a physicist will query the reconstructed data. A typical query might
select 3 properties and look for events satisfying a range of conditions on
those properties. The events that
satisfy the query may be spread over many files and over many tapes.
One
of the tasks in this proposal addresses an index over the large number of
properties (100-200) and a large number of objects (108 events).
Another part of the proposal seeks to optimize robotic tape system
access. We also address parallel
access from disk and tape systems in other tasks.
Back
to the table of contents
4.
Software Process and Risk Management
Overview: The SDM Center software framework will be developed
as a monolithic coordinated set of components by a geographically distributed
and diverse team of scientists and engineers. The development and deployment
plan is a 3-year effort based on an iterative and evolutionary prototyping
approach utilizing a combination of proposed research, development and
integration activities. As such, major capabilities will be prototyped and
delivered for application use within the first 18 months. This will enable
application scientists to test delivered components and provide feedback in a
timely fashion. As the SDM Center framework matures, the Center will work with
application users and other SciDAC teams to identify integration and
transition mechanisms for a long-term support and evolution to all the SciDAC
applications.
Management:
We will use centralized configuration and project management, with distributed
software specific development activities, including verification, validation,
testing, and optimization. Our development teams will be smaller peer-level
production teams centered on different subsystems of the overall product.
There will be an overseeing software development advisory and management
board, and an overall software configuration and quality assurance group. NC
State University and ORNL will provide standards for software project
documentation, management and basic production including verification,
validation, testing and risk management guidelines, and will lead the quality
assurance effort. ANL will lead an effort on code optimization and tuning with
the important profiling and performance diagnostic capabilities. Project-level
software management and tracking meetings will occur at least once a month. A
combination of regular teleconferences, emailing lists, and personal meetings
with application users and SciDAC Collaboratory Pilot teams will assure the
timely coordination of development schedules, deployment tasks, and
user-driven interface design.
Development: Software development will be performed in
distributed environments appropriate for particular SDM subsystems. Software
configuration, and parts of
verification and validation control, e.g., version control and problem
tracking system, will be centralized, using, for example, third party web/CVS
hosting. The project source code will be made publicly available through, most
likely, licensing the software as open source.
Documentation: NC State University and ORNL will provide
standards for software project documentation. Specific subsystem documentation
will be at a granularity commensurate with the particular component. User
manuals for each software component will be provided as well.
Risk
Assessment: There are two basic classes of risk associated with this
project 1) the ability to complete the work on time within budget, and 2) the
significance and usefulness of the resulting project demonstration. Having
developed many components of this project on schedule and within budget, we
believe that the first risk is quite small. The later class of risk is higher
in that this type of integrated end-to-end capability has not been
demonstrated previously. Many of the individual approaches have been proven
and widely used, but not shown to work together, or to be effectively extended
to all the SciDAC applications. Open source shared version management strategy
and user feedback-driven approach, described above, will decrease this type of
risk and assure the success of the project.
Dissemination: The SDM Center software framework will be made
available to a broad scientific and research community through a coordinated
set of activities including:
-
Licensing
the software as open source
-
Maintaining
SDM Center Web Server providing access to benchmarking results, hardware
specific implementations, multiple software versions, manuals, and training
materials
-
Hosting
software download ftp/web sites
-
Providing
documentation and software technical support to the user community
-
Providing
training for the use of software and exchange of information through
workshops, seminars, and emailing lists.
Reaching
out to the community through newsletters and electronic announcements of, for
example, relevant new software or improvements, and through presentations and
publications in conferences, journals and other professional forums.
Back to the table
of contents
5.
Organization
The Center Director, Arie
Shoshani, will assure the coordination of the various tools, monitor the
progress of projects, oversee the development of a web site, and schedule
joint meetings. Each institution has designated one "coordinating PI", as shown on the cover page.
An executive committee
composed of the center director and the coordinating PIs will oversee the
direction and the progress of the center. Five technical leads
have also been selected to provide vertical integration and coordinate work
within each thrust area: area 1 Bill Gropp, area 2 Alok
Choudhary, area 3 - Nagiza Samatova, area 4 Terence Critchlow, and the
agent technology work will be overseen by Tom Potok.
To assure the usefulness and quality of the Centers work, an advisory committee made of representatives of other centers and
application pilots, as well as external experts, will also be organized. In
addition to its formal role, this committee will help improve communication
and coordination between centers and pilot programs by fostering discussions
between them.
Back
to the table of contents
6.
Proposed work by thrust areas
In this section, we present the
details of the proposed work organized by the thrust areas. Each thrust area
is decomposed into the appropriate tiers, and each tier has one or more
related tasks. Each task is referenced by a label denoting its associated
thrust and tier, for example task 1a.i is the first task of thrust 1 within
tier a. It is important to note that while each task has an associated set of
deliverables, because of the interdependencies between tasks, some involve
institutions not directly responsible for implementing the task. The technical
leads will help ensure these deliverables are met. Each laboratory is involved
in three to four tasks, and each university in one to three.
Back to the table of
contents
6.1
Storage and retrieval of very large datasets
1a.i)
Optimization of low-level data storage, retrieval and transport (ORNL)
(Storage level activity)
Background and Significance
The
Probe testbed, with sites at ORNL and NERSC, was formed by MICS to develop and
test high-bandwidth distributed storage and network technologies. Primary
emphasis has been on tuning storage and network equipment and software,
protocol testing and High Performance Storage System (HPSS) projects.
Preliminary Studies
More
effective high-bandwidth transfers of very large datasets are being pursued in
four threads. One thread optimizes blocksizes and equipment configuration to
improve transfer rates. A second thread implements a TCP-friendly UDP service
to investigate recovery from dropped packets; the best of those mechanisms
will then be applied to TCP. A third thread will test a beta version of the
AIX operating system, which provides improved TCP/IP performance over lossy
networks. The fourth thread involves deploying machines at ORNL and NERSC to
evaluate ATMs effect on TCP performance and to evaluate Web100 kernel and
application extensions for improving TCP throughput.
A
second thrust is enhancing the Hierarchical Storage Interface (HSI)
application, a widely-used user interface to HPSS. File transfer between two
or more HPSS installations was an early Probe project.
Gigabyte
System Network (GSN, 6.4 gigabits/second) testing is a third thrust. The goal
of the project is to use this equipment in the visualization of supernova
simulations.
Fourth,
we are investigating new protocols for data transfer, e.g., Scheduled Transfer
and Storage over IP.
Fifth,
Probe has established a collaboration with Professor Tom Wiggen of the
University of North Dakota (and his graduate students) to develop a simulation
model of HPSS.
Research
Design and Methods
ORNLs
Probe site will participate in two ways in this ETC; logistical support of the
work of the other activities in this ETC proposal providing a place to
be and engaging in new research activities and those that build
upon existing projects. We are pleased to note that several vendors (Genroco,
StorageTek and IBM) have agreed to collaborate in the activities of this ETC.
A
Place To Be
In
the place to be role initial development work of the ETC will take place
in the ORNL Probe installation. This arrangement would provide several
platforms (requiring and demonstrating compatibility with distributed
operation), dissimilar platforms (requiring and demonstrating platform
independence), Gigabit Ethernet networks (necessary for effective distributed
operation) and disk and tape storage capacity. This ETCs work is relevant
to several Application Pilots; considerable quantities of data from each Pilot
will be used in developing and demonstrating the relevance and value of the
ETCs products.
After
technologies are tested and proven in the ORNL installation, testing will
expand to the NERSC Probe site to investigate latency-induced difficulties
associated with the wide-area network. Final testing will include other
installations to ensure there are no surprises resulting from wider
distribution.
Research
and Development Activities
The
general form of Probe activity will be to identify, acquire, implement and
tune new technologies important to the ETC -- new software, new storage or
network protocols and new equipment. Vendor collaborations will be valuable in
gaining early access to the technologies.
In
some areas marketed technologies will be insufficient for ETC needs. Probe
staff and resources would be applied to research and development to satisfy
that need. In particular, current technology is inadequate for bulk transfers
over the wide-area network, access to hierarchical storage and high-bandwidth
visualization.
1a.ii)
Parallel I/O: improving parallel access from clusters (ANL, NWU)
(Storage level activity)
Background and Significance
As
the benefits of parallel I/O systems have become known to application
programmers, the effort to fully exploit these systems has grown.
The viability of large-scale clusters has provided environments where
hundreds or thousands of processors are available for computation, and I/O
resources must be somehow matched to these computational resources. Simultaneously the complexity of the data stored by
applications has grown, and the functionality desired from storage systems by
today's scientific applications exceeds the capabilities of existing systems.
Efforts such as the Hierarchical Data Format (HDF ) attempt to address
these desires by building on top of existing file systems [HDF99].
Unfortunately some potential optimizations, in particular more intelligent
data distributions and storage of additional metadata, are more effectively
implemented within the file system itself.
Recently the support of ``extended attributes'' has attracted attention
in more mainstream applications as well, such as in the reiserfs local file
system design [namesys01].
Preliminary Studies
The
Parallel Virtual File System (PVFS), originally developed at Clemson
University, has grown from a research project into a useful tool both for
researchers and for data storage in cluster environments [CLR+00].
PVFS provides striping of file data across multiple nodes in a cluster
and implements a POSIX-like interface with native support for simple-strided
accesses [NKP+96]. The system
exposes file data distribution to the application, allowing the application
limited control over the data striping. In practice aggregate bandwidths of
over 3.0 Gbytes/sec have been attained using the PVFS system on the Argonne
Scalability Testbed [Chiba00], and PVFS is positioned as the leading candidate
parallel file system for Linux clusters.
Other shared file system approaches, such as GFS [PBB+00], are strong
in other aspects, but have not shown themselves to scale to large clusters.
Our
work in the ROMIO MPI-IO project has shown that matching application access to
data distribution on disk can provide one or more orders of magnitude
improvements in performance [TGL98], and exposing this information aids in the
process of matching access to distribution.
This supports the claim that file system support for
application-tailored data distributions would be of direct benefit.
Additionally,
in the PASSION project at Northwestern University, it has been demonstrated
that sophisticated data distributions and layouts can enhance the performance
of applications significantly both in regular and irregular data distributions
[CTB+96]. This was further
demonstrated in the VIP-FS (Virtual Parallel File Systems Project) which
extended the idea of data distributions to file systems in network of
workstations [HRC95].
We
have also examined the use of databases in conjunction with file systems for
storage of this metadata [CKN+00, LSC00].
This requires additional software to handle coordination of database
and file system data but provides a very high level of support, allowing
arbitrary database operations to be performed on this information.
This work highlights the benefits of storing additional metadata and
provides insight into the issues in implementing this type of system.
Research Design and Methods
We
will implement a set of enhancements to PVFS in order to directly address the
needs of applications storing complex data sets.
There are two important areas in which improvements may be made:
application-specific metadata storage and additional data distributions.
We will extend the PVFS file
system to include a flexible extended attribute interface, allowing
application and library writers to natively store metadata directly alongside
file data. The goal here would be to take lessons from the Data Management
Project sponsored by DOE at Northwestern University and adapt and extend them
to work in this new environment, where the file system stores attributes for
storage and access patterns along with other metadata. ANL and Northwestern
University will jointly work on accomplishing this goal.
This should be of direct benefit to projects such as HDF in that it
will provide a direct mechanism for storage of this information.
This should alleviate inefficiencies in storing HDF data seen when
using traditional files only.
The
second area of enhancement is in the physical distribution of data.
PVFS currently only provides a simple striping distribution.
Many application access patterns do not fit this type of distribution,
and as a result it has been shown that the support of additional distributions
can have a significant positive impact on performance.
One such distribution is chunking of file data in multidimensional
datasets. This type of distribution allows for improved access to subsets or
sub-blocks of file data across a number of dimensions.
Traditional row-major and column-major distributions often perform
poorly in comparison.
ANL
and NWU will jointly work in designing and developing metadata storage within
the framework of PVFS and implementing the new data distributions.
NWU will provide input in application access patterns, metadata storage
in similar environments, and matching data distributions to these patterns,
while ANL will provide the experience with the ROMIO project and the internals
of the PVFS system needed to perform these modifications.
To
provide archival storage for files in PVFS, we will work with HPSS developers
to investigate alternatives to the PVFS POSIX interface for data transfers to
and from HPSS.
1b.1) MPI I/O: implementation based on file-level
hints (ANL, NWU)
(File level activity)
Background and Significance
The
MPI-IO interface, part of the MPI 2.0 message passing interface specification
[MPI97], has become the industry and research standard for parallel I/O,
providing a rich interface for interaction with a variety of specific data
storage back-ends including traditional file systems, parallel file systems,
and tertiary storage. One
component of this interface is the ability to pass ``hints'' to the underlying
storage system which allow the system to tune its behavior.
The
types of information that might be useful to an underlying storage system
include but are not limited to quality of service (QOS), intended use (e.g.
scratch space vs. persistent file), and access pattern information.
QOS information is particularly important in distributed computing and
real time environments, where reservations are often necessary in order to
maintain predictable performance [RFG+00].
Intended use information can help the underlying file system make
decisions on allocation and policy for file storage. For example, allowing applications to control the level of
redundancy used in storing a file would allow applications to trade
performance for reliability. In
the case of a scratch file the application could specify no redundancy in
order to maximize performance, in some cases resulting in data held in cache
never actually reaching the disk. Knowledge
that a dataset will be accessed in subsets across a number of file dimensions
could be used to select a more optimal data storage distribution. The passing
of access pattern information into the MPI-IO layer can allow the intelligent
use of additional storage distributions in order to match the pattern. This is the hook which allows applications to easily take
advantage of the new distributions discussed in Section 1a.2.
Preliminary Studies
ROMIO
has become one of the most popular implementations of MPI-IO available today
[TLG97]. The ROMIO MPI-IO
implementation uses an abstract I/O device interface (ADIO) which defines a
basic set of operations on which MPI-IO is built [TGL96].
MPI-IO support for a specific storage system is then enabled by
implementing this set of operations only, simplifying the process greatly and
allowing for a significant shared code base within ROMIO.
ROMIO has been ported to HP, SGI, Beowulf, and Compaq and is the
primary MPI-IO implementation for these platforms.
As a research tool, ROMIO has been used as a platform for evaluation of
I/O optimizations such as ``data sieving'' and ``two-phase I/O'', sparking
vendor interest in these techniques [PTB+2000].
The
same work which motivates the extensions mentioned in Section 1a.2 also
indicates the need for a more expressive interface at the MPI-IO layer.
By implementing additional hints in the ROMIO implementation we enable
applications to better express their I/O needs through this standard
interface.
It
is important when implementing such additions that provisions be made for file
systems without direct support for these new hints.
In order to account for this, an abstraction layer will be utilized
within ROMIO to handle both cases where direct support is available and those
where it is not, following the design of the ADIO interface.
Our
previous work in the MPICH-GQ implementation, in conjunction with grid
developers, has given us insight into QOS issues in the message passing arena
[RFG+00]. This insight should be applicable in I/O as well.
Research Design and Methods
ANL
will provide the expertise with ROMIO and MPI-IO while NWU will develop a way
to extract, describe and provide access pattern hints through the MPI-IO hints
mechanism. Furthermore, ANL and NWU will jointly develop a mechanism to
provide and use quality of service within the framework of MPI-IO. NWU has
also been porting different applications to MPI-IO; NWU will use these
applications to evaluate the performance of the newer versions of MPI-IO with
the propose optimizations and enhancements.
This
will tie in with the LLNL work in application access pattern information as
well, providing a mechanism through which they can impart knowledge down to
the file system layer (when supported).
We
will also interact with the High Performance Storage System (HPSS) development
group to discuss the integration of ROMIO hints and optimizations into HPSS
MPI-IO. ROMIO can also
potentially exploit HPSS file access APIs through ROMIOs abstract device for
I/O layer (ADIO).
1c.i)Optimizing
shared access to tertiary storage (LBNL, ORNL) (File level activity)
Background and Significance
A
major bottleneck in analyzing the simulated/collected scientific data is the
retrieval of subsets from the tertiary storage system.
This is because of the inherent mechanical nature of tape systems and
sequential file access from tape. Typically,
large experiments (such as high energy physics) or large simulations (such as
climate modeling) generate terabytes of data that are organized as files in
the tertiary storage in the order they are generated.
For example, in high energy physics the experiment data is stored as it
is generated in time. Similarly,
in climate simulations the data is generated and stored in file by time steps
(i.e. the data for all variables, over all spatial point for a single time
step, followed by the data for the next time step, etc.). For a given query,
only a subset of the files needs to be accessed, and only a fraction of the
data in each file is needed. Typically less than 10% of each file is used by a
query. Therefore, we need to find
ways of minimizing the number of times files are read from tertiary storage,
by maximizing the sharing of files read from disk cache by overlapping
applications. Further, we need to
use methods that dynamically reorganizes data as it is read so that the data
accessed most ("hot data") is available from disk.
Preliminary
Studies
LBNL
has developed a software component as part of a system called STACS [STACS] (a
Grand Challenge High Energy Physics project), whose purpose is to minimize the
access from tertiary storage by optimizing the use of a disk cache, as well as
clustering file access requests to the same tape.
This component, which we refer to as the Hierarchical Storage Manager (HRM)
[BSSN00], is now in use as part of the STAR project.
It was designed to interface to the HPSS mass storage system. If HPSS
is busy, it queues the request, rather than refusing the access.
As such, it acts as a throttling system in front of HPSS.
If HPSS break down while a file is being transferred, it waits till
HPSS recovers, and re-issues the request.
It also reorders the request to HPSS so as to maximize reading files
from the same tape, and avoid remounting the same tape if possible.
Research
Design and Methods
The HRM module is currently integrated as part of the STACS system.
The disk cache management resides in another STACS component.
Our first goal is to make the HRM an independent module with its own
disk cache management. Second, we
plan to generalize this module, make it robust and fault tolerant and
package it so that this technology can be used by various scientific projects.
Third, we will work with and take advantage of the optimized block size
high-bandwidth transfer and HPSS-related activities being pursued in the ORNL
and NERSC Probe project. In particular, we plan to interface to the HSI system (see
task 1a.i), which provides more efficient access from HPSS by using double
buffering techniques. Fourth, we
plan to investigate the use a reserved space of cache for storing re-clustered
files that reflect the actual access to parts of files. We call this methodology "object granularity caching
strategy". For example, in
HEP only a small number of objects (called "events") are used when a
file is read. By storing only the
used objects in a disk cache we will have a much better utilization of the
cache for "hot data". To
accommodate that, we'll rely on enhancements to the high-dimensional index
(see task 2c.i) to reflect the availability of objects in the disk cache.
We are targeting initially the HEP application area, and will work
closely with the Particle Physics Data Grid (PPDG) Collaboratory pilot.
It provides a rich environment for using the HRM, since it involved
real six physics experiments.
Back
to the table of contents
6.2
Access optimization of distributed data
2a) The
cell 2a in Figure 1 will rely on Grid technology developed by others, and in
particular the Globus project at ANL and the SciDAC Grid Middleware projects.
2b.i) Integrating
with Grid I/O (ANL)
(File level activity)
Background and Significance
Grid
computing creates new challenges for applications wishing to perform I/O. In particular, grid I/O facilities, such as gridFTP, do not
directly implement traditional file system interfaces.
New solutions are needed to bridge the gap between traditional methods
of file access and these new technologies.
An
implementation of MPI-IO which could interact with grid technologies is the
solution we propose for bridging this gap.
The flexibility of the MPI-IO interface, especially with respect to its
consistency semantics and the hints mechanism, provide the necessary means for
communicating I/O needs to the underlying grid infrastructure while
simultaneously maintaining a standard interface.
This will allow applications to access grid resources without
modification provided they are using the MPI-IO interface already.
Preliminary Studies
These
activities will coordinate and collaborate with the Grid developers to ensure
that this coupling is appropriately designed and implemented.
We have interacted closely with these groups in the past to integrate
the MPICH message passing implementation with Grid technologies (MPICH-G2) and
quality of service support (MPICH-GQ) [RFG+00].
As
mentioned before, the ROMIO MPI-IO implementation utilizes an abstract I/O
device interface (ADIO) in order to ease the inclusion of support for new
underlying storage technologies [TGL96].
Our experience with ADIO implementations will pave the way for this
work.
Research Design and Methods
We
will implement an ADIO component for ROMIO which can communicate with existing
grid I/O services, allowing MPI-IO applications to interact directly with
these same resources. The MPI-IO
hints mechanism, previously described, will provide necessary grid-specific
information including quality of service requirements.
In
addition to hooking into grid I/O through the MPI-IO interface, PVFS is
currently being investigated as an option for data storage in grid storage
clusters (e.g. Gbox). In this
role PVFS provides a high-performance back-end for a collection of GridFTP
servers. The GridFTP servers
query PVFS for data distribution and optimize their access to PVFS storage
based on locality information. PVFS
handles storage of metadata and striping information, allowing the GridFTP
developers to concentrate on other aspects of the system.
This
effort directly ties to the work proposed by Foster and Kesselman in [FK01],
particularly in the areas of Data Grid and end-to-end management middleware.
2c.i)High-dimensional
indexing techniques (LBNL) (Dataset level activity)
Background and Significance
Many
large datasets can be considered high-dimensional because they contain a large
number of attributes that may be queried.
For example, High Energy Physics (HEP) data contains more than 500
searchable attributes that describe properties of the objects in the
experiment data. Since in
scientific databases the number of such objects is measured by 100's of
millions to billions, searching the attribute space is a daunting problem.
When a user expresses a query over these attributes to select a desired
subset of the data, usually a small number of attributes are used in a single
query. This presents a
significant challenge that is referred to as the curse of
high-dimensionality in data management.
The traditional indexing techniques (such as B-tree, hash) are
inefficient for datasets with a large number of attributes.
Since only a small number attributes are involved in a particular
query, only a small portion of the index is likely to be use to resolve the
query. This usually leads to
inefficient and unacceptably slow indexing of the data.
The same is true of known multi-dimensional indexing methods (such as
R-trees) that scale only up to 6-7 dimension before they become ineffective.
Preliminary
Studies
Our
basic approach to solve this problem is called vertical partitioning.
In essence, we treat each individual attribute separately.
In order for this approach to be successful, we need effective
strategies to index each attribute and to combine the partial results from
each attribute. From our
research, we have found that bitmap based indexing schemes may satisfy both
requirements. We use bitmap based
schemes to index each property and use compression techniques to reduce the
space requirement [John99]. The
partial solutions can be represented as bitmaps as well. Since bitmaps can be easily combined, the partial solutions
can be easily combined to answer user queries.
We
have developed a prototype query processing software implements a bitmap based
scheme called bit-sliced index [. This was done as part of the STACS system
developed under the High Energy Grand Challenge project [STACS]. The prototype
software package has been successfully used with the High Energy STAR
experiment at BNL. It processes a
typical user query in less than a minute.
Based on our previous test, processing the same query using a
commercially available database system may take orders of magnitudes longer.
Research
Design and Methods
Once
an index is built, it can be tens of gigabytes in size for typical large
datasets. To make out prototype software package useable for
high-dimensional data from other applications, a number of important features
are needed. These will make the
product more general purpose, practical to administer, as well as add
robustness. We plan to apply and
test this software package initially to experiments participating in the PPDG
pilot program, as mentioned in task 1c.i
-
Support for
NULL value. The null value is
need to indicate an invalid value, a value not yet computed or an
indeterminate value. We plan to use a bitmap to represent whether a value is
NULL. Given that compressed
bitmaps are used elsewhere extensively, this additional bitmap should be
relatively easy to add.
-
Support for
updating the index. The
prototype query processing software assumes that data is only appended.
This is a realistic assumption for applications that produce data
continuously as is the case with experiments and simulations.
This simplified our implementation of the initial system. However,
this assumption does not always hold. To
make this indexing method general we need to support any modification.
Currently, modifications require that the software be restarted to
rebuild the index. The process
of rebuilding the index and restart the software take many hours on large
indexes, such as the current STAR data.
This functionality will be added.
-
Updating an
index requires the interrupted use of the index. This is unacceptable for large indexes. Similarly, rebuilding an entire index because of changes or
additions is prohibitive as it takes many hours for such large indexes.
We will develop a strategy for incremental updates with mirror
indexes that avoid interruption in the use of the index.
-
Support for
recovery from failures. Two kinds of recovery will be considered, restoring
the state of system after abnormal termination and restoring the index to
its previous state after addition of erroneous data. Both types of recovery operations are important in order to
ensure robustness of the software. We
plan to add these feature to the system.
-
Application
program interface (API). The
prototype software is a stand-alone CORBA server that interacts with a
number of other CORBA programs. This
distributed setup is certainly useful in some cases; however, allowing
access through mechanisms other than CORBA is also desirable.
For example, we may provide the core functionality as a library so
others may build their own database software, or we may provide a web based
interface for query processing.
-
Use index
with "signature" metadata. By
signature metadata, we mean descriptions of the runs that generated the data
as well as the conditions under which the data was generated, such as device
parameters. Typically such
metadata is small and can be managed by a conventional commercial database.
However, queries for selecting data may want to use the attributes
(managed by the large index), in combination with the metadata are not
possible yet. We will address the problem of providing a federated solution
of accessing both.
Back
to the table of contents
6.3
Data mining and discovery of access patterns
3a.i)Adaptive
file caching in a distributed system (LBNL)
(Storage level activity)
Background
and Significance
This
task is concerned with investigating the performance and optimization of file
level disk cache replacement policies for automatic file migration in a
distributed setting. We are
concerned primarily with scientific workloads, e.g., those arising from high
energy physics. The goal of our
work is to develop improved cache replacement policies, which will be
implemented as pluggable policy modules in a disk cache manager.
There
are a number of factors that characterize the problem(s) being considered:
-
workload model
for file references
-
storage system
architecture (granularity of accesses, multi-level storage hierarchy,
distributed system setting)
-
network
topology
-
objective
function and cost model for accesses
-
replication
policies (how many replicas, which replicas may be used, multi-tier caching,
etc.)
-
replacement
policies for caches (e.g., LRU, LRU-K, STOCHOPT, HOPT)
-
level of
detail of modeling
Workloads
differ dramatically across applications, with respect to both access patterns
and access granularity (files vs. objects, file sizes). Workload models are
statistical models of the file access patterns that attempt to model the most
salient aspects of the file accesses. However, because large scientific
databases are stored on tertiary storage, scientific workloads of accessing
such files are characterized by large, relatively uniform file size, typically
about 1 gigabyte each. File requests are often batched (i.e., the subset of
files which contain the results of a query) and (in many cases) can be
processed out of order. For example, experimental physics object, called
"events", stored in files are independent of one another.
Workloads
used for studying cache performance may either be traces or synthetic.
Traces are taken from existing (often
centralized) systems (HEP experiments). Assuming that the file reference behavior is independent of
the storage system architecture and policies, these traces are then applied to
novel simulated storage systems (policies). In some cases the traces may be
modified, e.g., to assign geographic locations to file access requests so as
to model the distributed system aspects. Alternatively, simplified statistical
models (e.g., Poisson point processes, independent reference models, LRU
models, etc.) of the file reference workloads are constructed.
These synthetic workload models may either be used for analytic models
(in those few cases which are tractable) or (more commonly) for Monte Carlo
simulations of the proposed storage system architectures and policies.
Synthetic workloads are necessary for analytical modeling and are often
desirable for exploring various storage system configurations and policies -
since they can be easily scaled and adjusted to explore the relationship of
policy performance to various aspects of the workload.
Preliminary
Studies
Simple
workload models (e.g., Poisson processes with file dependent arrival rates),
with parameters estimated from workload characterization will be the starting
point of our analytical models of cache system performance of some simple
caching policies. Our earlier
work [Olke83] on single site, two level file system caching policies showed
that we could characterize optimal replacement policies in terms of the hazard
rate (a.k.a. failure rate) of the probability distribution of the file
inter-reference times, file size, and tertiary storage access costs.
Research
Design and Methods
There
are three aspects to our approach:
We
will consider various cache replacement policies. Such policies decide when
and which files are evicted from the local or archival or mid-tier caches to
make room for incoming files can vary. Commonly used replacement policies
include least-recently used (LRU), least frequently used (LFU), LRU-K (an
finite memory approximation of LFU), and various more complex policies which
take file reference behavior, file size, and remote access costs into account.
Since
file system cache performance is dependent on file system reference behavior,
we intend to use traces of file system activity (opens/closes, etc.) from the
BABAR physics experiment at SLAC. We plan to do statistical analyses of the
file reference process(es), i.e., file inter-reference time distribution, and
to characterize the size distribution of the files.
Simple
workload models (e.g., Poisson processes with file dependent arrival rates),
with parameters estimated from workload characterization will be the basis of
our analytical models of cache system performance of some simple caching
policies. Our earlier work on
single site, two level file system caching policies showed that we could
characterize optimal replacement policies in terms of the hazard rate (a.k.a.
failure rate) of the probability distribution of the file inter-reference
times, file size, and tertiary storage access costs.
More
realistic performance modeling of the performance of cache replacement
policies will require simulation computations. Simple simulations will permit
us to calculate performance measures such as cache hit ratios. More
sophisticated (and cpu intensive) simulations based on queuing models will
permit us to model network and input/output device delays more realistically.
We
plan to consider progressively more complex caching system designs and
policies. We will commence with simple single site two-level file caching,
then progress to more general network models, multiple file replicas, and
eventually to multi-tier hierarchical caching policies.
The multi-tier site model assumes that there are regional centers
serving a community of users.
3b.i)
Dimension reduction and sampling (LLNL) (File level activity)
Background
and Significance
As
we have described in the section on Scientific Applications, data from
simulations such as climate modeling, or experiments such as the STAR High
Energy Physics experiment, are not only massive, but also have high
dimensionality. This makes it
difficult to efficiently retrieve chunks of data distributed across multiple
files or multiple storage media. Cluster analysis techniques (task 3c.1) are
often used to address this bottleneck by improving the way in which the data
is stored so that its retrieval can be more efficient. In addition, these
techniques can also be used to minimize the amount of data that needs to be
transferred and stored. However,
current clustering algorithms can be impractical for handling extremely large
data sets that are also very high dimensional. In this task, we will use
dimension reduction techniques to make clustering tractable in very high
dimensions. The basic idea is to identify the most important attributes
associated with an object so that further processing can be simplified without
compromising the quality of the final results. This work will not only help
the clustering techniques proposed in Task 3c.1, but also reduce the number of
attributes that must be considered in the high-dimensional indexing techniques
work proposed in Task 2c.1.
Preliminary
Studies
There
are several different methods that can be used to reduce the dimensionality of
a data set. Depending on the properties of the data, some methods are more
suitable than others for a given data set. It is also difficult to a priori
identify which method is likely to be the most appropriate one for a data set.
The simplest approach to dimension reduction is to identify important
attributes based on input from domain experts. Another approach we are
currently exploring is Principal Component Analysis (PCA) which defines new
attributes (principal components) as mutually-orthogonal linear combinations
of the original attributes. For many data sets, it is sufficient to consider
only the first few principal components, thus reducing the dimension. However,
for some data sets, PCA does not provide a satisfactory representation.
Our conversations with Dr. Ben Santer of the Program for Climate Model
Diagnosis and Intercomparison (PCMDI) at LLNL have indicated that this is the
case with typical climate data sets. In addition, scientists often collect
data on a problem incrementally, and are therefore interested in having the
dimension reduction techniques applied to a growing data set with relatively
little added cost.
Research
Design and Methods
To
address this need for more appropriate dimension reduction tools, we will
consider several different approaches. First, we will consider attribute
selection techniques using genetic and evolutionary algorithms [CK01]. These
techniques enable effective searches in high dimensional spaces. This work
will leverage our existing library of parallel evolutionary algorithms, which
was developed as part of an LDRD effort that concludes in FY01. Next, we will
consider generalizations of PCA, such as projection pursuit and non-linear PCA,
as well as alternatives to PCA, such as Independent Component Analysis (ICA).
These have been shown to improve retrieval performance while reducing
storage and are currently being considered by climate scientists [BM97,
MMS+94]. In the context of this work, we will also collaborate with LBNL
scientists in order to use ideas from their HyCeltyc algorithm that combines
sampling and dimension reduction within a hierarchical method for identifying
clusters in data [OSH01].
In
addition to exploring dimension reduction techniques that are more appropriate
to the applications described in this proposal, we will also research
efficient ways of applying these techniques to the case where the data is
being collected incrementally. A
simplistic approach to this problem is to apply the technique each time the
data set is updated with new data. But since the techniques are very compute
intensive, this approach is impractical. To address this problem, we will
explore the applicability of ideas originally developed for distributed
dimension reduction.
As
the data sets become larger, it is likely that the above dimension reduction
techniques will become computationally prohibitive. In such cases, we will
conduct our work using a smaller sample of the objects. However, in the case
where the scientists are interested in searching for anomalies in their data,
this sampling must be done with care, as the anomalies are likely to be missed
in the sample selected. To remedy this, we will apply techniques developed in
data mining for sampling a data set in the presence of rare events [FS95].
Our
plan is to initially start work with some climate data sets - the exact data
sets will be identified in collaboration with the climate scientists at LLNL
and the ORNL scientists working on task 3c.1. We have chosen climate as our
initial application as we have worked in this area before. Once the techniques
for dimension reduction have been established in the context of climate data,
we will apply them to High Energy Physics data from STAR. At this stage, we
expect to conduct research on the sampling part of this task.
The software will be made
accessible to the domain scientists as we develop it. This will involve close collaboration with climate scientists
at LLNL, as well as HEP scientists at BNL. As the techniques developed in this
task can support data mining as well, they will also be made available to
domain scientists who wish to use them for analyzing their data.
The scientists involved in this
work (Imola Fodor and Chandrika Kamath from LLNL) have extensive experience in
dimension reduction techniques, evolutionary algorithms, high performance
computing, and statistics. They have previously been involved in the analysis
of climate and astrophysics data.
3c.i)Multi-agent
based high-dimensional cluster analysis
(ORNL) (Dataset level activity)
Background and Significance
As
previously noted, network bandwidth is and will remain a major bottleneck in
transferring very large datasets, especially across WAN. Migration of massive
(terabytes) datasets that result from an up to a month-long simulation run to
a temporary archive for first-analysis and subsequent migration to a standard
archive are an essential part of collaborative research, such as global
climate modeling. Minimizing the amount of data that needs to be transferred
and stored will continue to be an important need. Data compression utilities
(e.g., gzip) are almost the only way currently used for this purpose. This
task coupled with task 3b.i seeks for a more intelligent approach in
addressing this need. The objective of this task is to develop ASPECT
(Adaptable Simulation Product Exploration via Clustering) toolkit that
provides simulation scientists with Capabilities to:
-
Perform
dynamic first-look data mining for monitoring and steering a
long-running simulation. Such an on-demand feedback (snapshots) enables
scientists to decide whether to terminate a simulation, restart it with a
new set of parameters, or continue. This any-time decision making
capability can potentially save a huge number of CPU cycles and a great
amount of storage as well as avoid unnecessary data transfers to temporary
archives. Most existing data
analysis tools do not support any-time dynamic analysis. They are
designed as post-processing tools. Due to high computational overheads and
much interference with a running simulation, interactive visualization and
remote computational steering tools such as CUMULVS [GKP97] are not
appropriate for these purposes as well.
-
Perform
distributed pattern query, search, and retrieval for comparing a simulation
output of interest with the ones that have been generated by different
models or initial conditions. In this case, for example, a queried
simulation output can be discarded because it matches one or more
archived simulation runs. Such
comparison of multiple distributed simulation outputs will be useful not
only for data transfer decision making but also for comprehensive evaluation
of existing simulation models and exploration of model parameter space. To
the best of our knowledge, no automated tools with such capabilities are
available.
-
Infer rules
relating fragments in two or more simulation outputs. An example would be a
rule such as an increase in the value of sea-surface temperature over the
South Pacific is likely followed by increase in precipitation over western
part of the U.S.
Preliminary
Studies
A
recent three-year LDRD effort on Analysis of Large Scientific Datasets
concentrated primarily on time series data [DFL+96, DFL+00].
Particularly, resulting techniques and algorithms that use local
modeling for global cluster analysis [DFL+00] will be useful in developing
capability #3.
Another
two-year LDRD effort on Statistical Downscaling of climate data developed a
set of preprocessing tools for separating trend, seasonal, and anomaly
components from climate model data fields before applying downscaling
regressions of the separate components onto regional data.
These preprocessing tools as well as the experience with climate model
output will transfer directly to capabilities #1 and #2.
ORNLs
current massive data mining research activity (under PROBE) recently produced
RACHET [SOA+01], a distributed clustering algorithm for merging dendrograms
from distributed data sets. The
algorithm provides a distributed merging capability for existing hierarchical
centroid-based clustering algorithms. This,
as well as subsequent results of the PROBE data mining activity will form the
clustering basis for capabilities #2 and #3.
Research
Design and Methods
We will be taking an iterative
approach to the development and deployment of ASPECT. This will enable
application scientists to test delivered components and provide feedback in a
timely fashion. Concurrently, we will perform research that will lead to more
accurate and efficient solutions in the long run. Initially, we will target
the climate simulation and modeling application area, and work closely with
the Accelerated Climate Prediction Initiative (ACPI) Avant Garde Collaboratory
pilot and possibly its LAB 01-09 expansion (if funded). This choice of climate
is based on our familiarity with the data due to our recent LDRD on climate
downscaling and on availability of the Probe testbed that provides a high
bandwidth connection to the rich PCMDI data repository.
Our first goal is to develop a component-based framework for ASPECT. The
overall concept and structure of the system implementation will be built on
top of HARNESS (DOE/MICS funded project) [BDG+99] that supports dynamically
adaptable parallel applications. In this framework, computational scientists
will be able to assemble personal subsets of data mining tools from the
provided repository of ASPECT plug-in modules. The computational core of the
system will be a repository of plug-ins required to provide a desirable
functional level of ASPECT.
Second,
we will develop a set of plug-ins sufficient to provide the capabilities
descried above. We begin with generalizing some climate time series (CTS)
tools used in our Statistical Downscaling work to deal with multiple climate
models and expanding them with dynamic capabilities to provide any-time
snapshots during the climate simulation run. The result can be used as a
monitoring tool with little interference (access to output files) with the
simulation. Such interference can be minimized by an MPI-IO-based
implementation of this tool with application access-driven data layout (task
1b.i). We will make the enhanced CTS tools robust and package them as ASPECT
plug-in modules. Since dimension reduction is essential here, the results on
dynamic dimension reduction (task 3b.i) will be integrated into ASPECTs
framework to improve CTS tool efficiency.
Next,
we plan to expand our multi-agent cluster analysis-based system, VIPAR
[PTS+01, PIS01], which enables dynamic and distributed information processing,
query, and retrieval. The expansion should let VIPAR handle time-series
simulation data. We will select
application-based similarity measures that are the most suitable for comparing
climate simulation time series and incorporate them into our distributed
hierarchical clustering algorithm RACHET.
This effort is the core of the task because of the way it is related to
other tasks in the SDM center. First, this effort will benefit from task 4 by
having a transparent interface with existing data archives. Second, clustering
simulation outputs (i.e., time series) based on their similarity will drive
physical data layout in case no hints to PVFS (task 1a.ii) are available, thus
reducing query response time and subsequent data movement for the purpose of
data layout optimization. Third, cluster analysis of multi-dimensional data is
often a necessary step for improving high-dimensional indexing techniques
(task 2c.i). Fourth, to make clustering massive (in terms of size and
dimensions) more tractable and effective, dimension reduction techniques (task
3b.i) have to be applied before clustering.
Finally,
we will develop a plug-in for in-depth analysis of fragments in multiple
heterogeneous time series by inferring rules about their interrelationships.
We will integrate our investigations on local modeling of time series
[DFL+00] with complementary efforts on fast pattern matching in time
series databases [KS97] to provide Capability #3. We will work closely with an
ORNL climatologist, David Erickson, to make sure that inferred rules are
climatologically meaningful.
3c.ii)
Analysis of application level query patterns (LLNL, NWU) (Dataset
level activity)
Background and Significance
As
previously noted, both the underlying format in which data is stored and its
physical location has a dramatic effect on the speed at which it can be
retrieved by various applications. If the data is to be read many times, it is
usually beneficial to format it to minimize access times, even if that
requires incurring a small additional overhead during the initial storage.
However, determining the data layout that minimizes the response time is a
significant challenge. In addition, when data is used by multiple
applications, such as different visualization, query, and analysis tools, and
each with different access patterns, this becomes even more complex because a
data format that decreases the access time for one application may increase it
for another. The objective of this task is to develop a suite of tools capable
of defining a data storage format that minimizes access times given historical
access patterns to similar data sets. By identifying such a format, these
tools would allow existing data to be rewritten in an improved format, but
more importantly, would also allow new data to be initially created in this
format by providing hints to MPI/IO. The key to obtaining the appropriate data
format is to analyze an accurate history of access patterns that includes all
references to the data, as well as high-level information about the
applications and users that drive these accesses. Previous work in this area
[SR98] often does not reflect patterns from multiple applications, and has
used only low-level access patterns to provide insight into the best data
layout. As a result of ignoring information such as queries, users, and
applications, this analysis misses larger trends that may lead to better
strategies within the overall interaction context. In addition to better data
layout within a file, these improvements may include new pre-fetching and
caching strategies at both the file and data set levels.
Preliminary
Studies
Because
of the importance pattern recognition and clustering play in the
identification of significant access patterns, both LLNL and NWU are providing
experts in this area. Roy Kamimura (LLNL) brings his expertise in feature
extraction and cluster analysis techniques, which are complemented by Wei-keng
Liaos (NWU) expertise in scalable and parallel techniques for data analysis
techniques. This expertise will be brought to bear analyzing meta-data
obtained from two sources. The
first is the impressive meta-data management system that has been developed
under the supervision of Alok Choudhary (NWU) [LSC00][SLC+00]. This system
records all accesses to data managed by its file system in readily accessible
meta-data. This meta-data will be integrated with additional meta-data
collected from the SimTracker system [LSS99] developed by Jeff Long (LLNL) as
part of the intelligent archive project.
This meta-data will include information at the application and user
levels such as which applications access the data, in what order the
applications are invoked, and the applications users invoke. Ghaleb Abullas
(LLNL) experience designing and developing the DataFoundry query engine
provides the expertise required to obtain and understand the meta-data,
interpret the results of the pattern analysis, and coordinate the transfer of
this information to the MPI/IO team. Finally, Nu Ai Tangs (LLNL) experience
developing the DataFoundry query engine makes her a valuable resource for the
development and deployment portions of this task.
Research
Design and Methods
We
will take an iterative approach to the design, development and deployment of
these tools. This will allow us to provide initial results quickly, while
continuing to perform research that will lead to better solutions in the long
term. In addition, because the
results of the analysis will only be as good as the meta-data provided, it is
critical the data access patterns, applications, and queries have a solid
foundation in real-world usage. Our
primary customer will be the same application group as for task 1b.i, and thus
we will most likely be using astrophysics data from the FLASH center. Our
interaction with this group will allow us to readily obtain the appropriate
usage information to form the basis of our research and provide a baseline
against which we can evaluate alternative data layouts.
Back
to the table of contents
6.4
Access to distributed, heterogeneous data
Background and Significance
The
Internet is becoming the preferred method for disseminating scientific data
from a variety of disciplines. For
example, there are currently over 500 genomic data sources from around the
world distributed over the web. This has resulted in information overload on
the part of the scientists, who are unable to query all of the relevant
sources, even if they knew where to find them, what they contained, how to
interact with them, and how to interpret the results. Thus instead of
benefiting from this information rich environment, scientists become experts
on a small number of sources and use those sources almost exclusively.
Enabling information based scientific advances, in domains such as functional
genomics, requires fully utilizing all available information.
We
are collaborating with researchers who lead the development of the Protein
Data Bank, create tools for protein sequence structure-function mappings, and
develop protein localization methods for Neuroscience. Through these
collaborations, we have developed an assessment of the scientists
requirements for knowledge-based information integration: Researchers need to
encode as part of their databases, complex scientific relations that connect
different experiments. Examples
are links between protein substructures, literature references, and protein
functions. Researchers may want
to access diverse data by approaches interleaving ad-hoc queries and
navigational queries. For example, they may first conduct a search for
co-localization of proteins in a neuron leading to a search for homologous
proteins, and in turn a navigational search for equivalent protein
localization in related species. The
multiple underlying databases need to interoperate semantically,
such that complex queries may cross the borders of the researchers own
databases and correlate experiments across multiple domains.
Unfortunately,
previous attempts to reduce the complexity of this information landscape
[CM95] [DOT97][BBB+98] by combining the independent sources into a federation
or data warehouse have met with limited success because of the large number of
available sources, and their dynamic nature.
Web based sources usually provide a forms-based interface to the data,
which enables the basic search capabilities required by the domain (often more
than just simple keyword searches). The underlying data is also often made
available in a flat file representation, and in special cases, direct access
to the underlying databases may be provided. Some sites allow specification of
the format and fields to be returned (to a limited degree). Most sites change
interfaces and data formats regularly. Query results are returned in an html
page designed for a human to interpret nicely formatted, but difficult for
a computer to interpret. The objective of this task is to simplify the process
of wrapping a data source interface and allow cooperating sites to easily
generate queriable wrappers for their data sources.
Preliminary
Studies
Investigators from
both LLNL and GT have been performing research on various aspects of the data
access problem for many years. Terence Critchlow was one of the initial
members of the DataFoundry data warehousing project [CFG+00], which developed
a novel approach to reducing the time required to define and maintain
mediators in a mediated warehouse architecture. This technology has since been
licensed by a biotech company for inclusion in their software. He has also
helped organize several relevant conferences and workshops including the IEEE
Meta-Data98 conference and the XEWA00. Ling Liu has been leading the
development of leading edge wrapper generation technology as the PI of the
XWrap project [LCH+99, LCH00]. The current version of XWrap to generate HTML wrappers is
available for public use at URL: http://www.cc.gatech.edu/projects/disl/XWRAPElite/.
Several graduate students contributed to the XWrap effort, including D.
Buttler and W. Han. Calton Pu has
been the PI of the Continual Queries and Infosphere projects that includes
XWrap effort as component technology. Other
useful component technologies for heterogeneous data access in the Infosphere
project includes the Infopipe toolkit [LPS+00, PSW01], which will integrate
wrappers and parsers for several data interchange formats including XML and
PBIO.
In
prior research at SDSC, Amarnath Gupta and Bertram Ludaescher have
demonstrated how image content (e.g., protein localization or dendritic
morphology) can be semi-automatically modeled (e.g., as feature vectors or
histograms) and used as a part of the conceptual model of a neuroscience
database [GLM00,LGM01]. With this level of content modeling they could express
queries on protein content comparison at a conceptual level. The
ontology-based framework proposed in [BCV99, MKS96, CGL99] was extended to situate
a piece of experimental data (like proteins in spiny branchlets) in its
anatomical context (i.e., placing branchlets as subparts of Purkinje cell
spiny dendrites, as well as containers of subcellular structures like the
smooth endoplasmic reticulum) by hanging off the data from a domain
map, a semantic network that represents how different anatomical entities
relate to each other [GLM00,LGM01]. Here, context
was defined as a complex neighborhood finding operation on a set of indexed
nodes of the domain map, and was used to query across different anatomical
resolution levels for the same anatomic entities.
In [LGM00, LGM01] Ludaescher and Gupta introduced the problem of
mediation of multiple (scientific) worlds, i.e., integrating semantic
information from indirectly connected information sources by using additional
domain knowledge. So far, they have integrated sources based on conceptual
models and have exploited techniques like schema-level reasoning to specify
integration rules that would otherwise be cumbersome to express. In particular, the view
definition problem, where sources are combined to construct integrated
views over which queries are formulated, was addressed by using a
deductive, object-oriented approach [FLO00] to evaluate declaratively defined
mediated views between information sources (e.g., from Yale University and
UCSD).
Research
Design and Methods
We
will be taking an incremental approach to the development of a wrapper
generator. Starting from the XWrapElite toolkit, we will develop the
next-generation software to create wrappers for complex and evolving
interfaces to data sources. This
new development will follow two main ideas.
First, the new tool will use a meta-data description of the interface
and the expected outputs to generate a wrapper for the source capable of
responding to queries sent by the SDSC query engine. The wrapper generator
also maps interfaces onto a collection of known service classes.
This mapping information is used by the query engine to find the
appropriate data sources on behalf of users.
Second, we are exploring a heuristics-based approach for automated
object extraction in HTML pages [BLP01].
An automated approach to object extraction has several practical
applications. The most relevant
application to this project is the development of automated methods to monitor
source interface changes and to repair the wrappers while minimizing
programmer intervention. Each of
these ideas will improve our wrapper generator significantly.
The meta-data description addresses the complex part of the data source interfaces.
The automated object extraction addresses the evolving
part of the data source interfaces. When
combined together, the new generation wrapper generator toolkit will
significantly alleviate the time delay and cost of manual maintenance of
source wrappers today. Finally,
we will integrate the wrapper generator with the Infopipe toolkit [LPS+00,
PSW01], which will provide quality-of-service systems software for information
flow applications such as digital libraries and electronic commerce.
In order to ensure
the applicability of the wrapper generator tool for complex, real-world
applications, we will work closely with Tom Slezak, head of bioinformatics for
the Joint Genome Institute and the Biology Research Program at LLNL, to
identify a large set of sources relevant to biologists current needs, and use
these sources to evaluate our tools. This domain is well known to both LLNL
and GT collaborators [BPG+96] and is sufficiently diverse and dynamic compared
to most other scientific domains. As
the next-generation wrapper generator tool matures, we will work with other
collaborators in the center to apply and evaluate it in other domains outlined
in this proposal. The faculty
PIs, GRAs, and the programmer will work together to produce and maintain
publicly released software such as the XWrapElite and PDBtool [BPG+96].
In the later years, Nu Ai Tang will lend her expertise in developing
robust software to this task.
Once defined, many
of the resulting wrappers will be integrated into an extended version of the
current SDSC system in order to provide semantically consistent access to
additional sources. The SDSC mediation services will be invoked via different
APIs. As part of the source
registration service, a new data source will be able to join the federation by
exporting its data model (e.g., relational, XML) together with its schema
(e.g., relational schema, XML Schema), query capabilities (e.g., SQL SELECT,
XPath queries) to a mediator. A source may also supply domain knowledge in the
form of logic rules (axioms). These rules specify how the information provided
by the source relates to other information previously registered at the
mediator. The mediator hosts one or more domain maps that serve as semantic
anchor points relative to which a source module can define its domain
knowledge. After a source has registered, a model reasoner will be developed
to check the newly registered concepts against the previously registered ones
and to infer possible subsumptions and inconsistencies.
User queries
against the mediation services client API will be composed of the integrated
(mediated) view, unfolded, and possibly optimized with respect to the given
semantic knowledge and query capabilities of sources. At the wrapper layer,
incoming queries from the mediator pass through the down API to the sources,
e.g., at a higher (collection) level using digital library
infrastructure such as the SDLIP protocol, at an intermediate level of query
languages (XQuery, SQL), or at lower level APIs such as DOM or SRB. Result
delivery from the sources (up API) can be driven from the mediator (pull mode)
or from the source (push). The overall query processing in the wrapper and
mediator layers will use both modes with suitable APIs to be developed during
this project.
Back
to the table of contents
6.5
Agent technology: enabling communication among tools
and data (ORNL, NCSU)
The goal of this technology is to
allow for easy and accurate interaction among tools and data. For example, an
astrophysicist may be looking to render an experiment as it occurs. Agents can
be used to interact between the storage and retrieval methods of the
astrophysics data (1a.i), the improvements hints found through the access
patterns of the data (1a.ii), and adaptive caching information of the data
(3a.i), so that information from these three different sources can be
effectively used to store and retrieve the data more efficiently. During a
simulation run, agents can retrieve streams of data for dimensionality
reduction (3b.i), and then provide the reduced data for further reduction
through clustering (3c.i). Finally, an agent can be used to provide the
reduced and focused information to visualization tools for rapid rendering.
This process currently takes days or longer to perform.
The challenge of integrating
software and data on a large scale is clearly not a new one. There are a
number of approaches such as data warehousing, object-request brokers, and
middleware-based libraries and tools. Data warehouses provide a means for
publishing and accessing a broad range of distributed, heterogeneous data.
Object request brokers (ORBs), and similar software bus and data
bus technologies, provide a way of accessing distributed objects and data,
as if the objects/data were local to the users environment.
Finally, middleware libraries and tools provide a layer above the data
and tools yielding easier way of system and data integration. They also
provide uniform data formats at the storage level.
Unfortunately, for very
large-scale systems these approaches require reworking much of the original
software, and data as well. A viable solution must be able to work with
minimal changes to existing tools and data, while at the same time
implementing the latest advances in new data collections and systems. Based on
our experience in this type of environment, we believe that the adaptive and
rational attributes of agent technology, and of its underlying communication
infrastructure, are ideally suited to address this challenge [IPP99, PIS01].
This is a new approach to this problem that we hope will provide a significant
reduction in the amount of custom written code used to bridge two or more
models.
Preliminary
Studies
We plan to leverage research from
a number of previous projects including ORNLs Collaborative Management
Environment [PEI99] and Virtual Information Processing Agent Research (VIPAR)
project [PTS+01], and NC States Models3 technology for EPA [DBN+96] and the
MCNC Environmental Decision Support System [BVP99].
Research
Design and Methods
We propose an architecture based
on a scientific data model that forms an ontology for scientific data and data
management tools. This ontology will allow software agents to begin to
interpret scientific data and adapt this data to the interfaces of data
management tools. A similar approach was taken in the DOE funded Collaborative
Management Environment project where an XML ontology and database interfaces
were created at ORNL and LBNL [PEI99]. From this ontology a number of agents
would be developed with expertise in application areas, data techniques,
storage techniques, and analysis techniques.
We will use ORNL developed Oak
Ridge Mobil Agent Community (ORMAC) framework to rapidly create agents that
can understand and communicate based on a new ontology. The data management
tools and the data would interact with the agent system via whiteboard
concepts, as we have demonstrated with our VIPAR system. Tools and data can
put a request for services on a whiteboard, from which an agent can be
dispatched to attempt to perform the task. One of the key research areas would
be to develop the capability for the agents to adapt to changes in the
scientific data environment, and to improve the quality of service of the
environment for the scientist.
Back to the
table of contents
The
technology we propose to develop, harden, and deploy, is relevant to multiple
application areas. The letters of
support from lead researchers from the areas of Astrophysics, Climate
Modeling, Bioinformatics, and High Energy Physics assure us of their interest
to collaborate and work with the SDM center team.
In particular, we have discussed and coordinated our proposal with the
leaders of following SciDAC proposals: the
Particle Physics Data Grid Collaboratory Pilot project (PIs: Richard
Mount SLAC, Miron Livny U of Wisconsin), the Earth Science Grid
Collaboratory Pilot (PIs: Dean Williams LLNL, Ian Foster - ANL), A
High Performance Data Grid Toolkit: Enabling Technology for Wide Area
Data-Intensive Applications (PIs: Ian Foster - ANL, Carl Kesselman - ISI),
and the DOE Science Grid: Enabling and Deploying the SciDAC Collaboratory
Software Environment (PI: Bill Johnston LBNL).
Back
to the table of contents
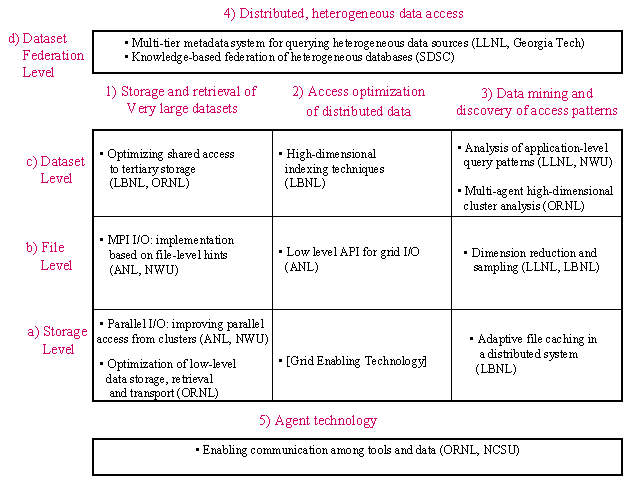
Figure 1:
Relationship between data management
software modules (tools)
[BBB+98]
P. Baker, A. Brass, S. Bechhofer, C. Goble, N. Paton, R. Stevens. TAMBIS
Transparent Access to Multiple Bioinformatics Information Sources. In
Proceedings of the Sixth International Conference on Intelligent Systems For
Molecular Biology ISMB-98. Montreal. 1998
[BCV99]
S. Bergamaschi, S. Castano, and M. Vincini, Semantic Integration of
Semistructured and Structured Data Sources, SIGMOD
Record 28(1), 54-59, 1999.
[BDG+99]
M. Beck, J. Dongarra, G. Fagg, A. Geist, P. Gray, J. Kohl, M. Migliardi, K.
Moore, T. Moore, P. Papadopoulos, S. Scott and V. Sunderam, HARNESS: A Next
Generation Distributed Virtual Machine, Special Issue on Metacomputing, Future
Generation Computer Systems, Elsevier Publ. Vol 15, No. 5/6, 1999.
[BM97] M. Beatty and B. S.
Manjunath, "Dimensionality reduction using multidimensional scaling for
image search," in Proc. IEEE International Conference on Image
Processing, Santa Barbara, California, October 1997.
[BSSN00]
L. M. Bernardo, A. Shoshani, A. Sim, H. Nordberg, Access Coordination of
Tertiary Storage for High Energy Physics Application, 17th IEEE
Symposium on Mass Storage Systems, March 2000 (MSS 2000).
[BVP99]
Balay R.I, Vouk M.A., Perros H., "Performance of Middleware for
Scientific Problem-Solving Environments," in Problem
Solving Environments, IEEE CS, 1999
[CFG+00]
T. Critchlow, K. Fidelis, M. Ganesh, R. Musick, T. Slezak. DataFoundry:
Information Management for Scientific Data. IEEE Transactions on
Information Technology in Biomedicine Volume 4. Number 1. March 2000. pg 52-57
[CGL99]
D. Calvanese, G. De Giacomo, and M. Lenzerini, Answering Queries Using
Views in Description Logics. In 6th International Workshop on Knowledge Representation meets
Databases (KRDB'99), 6-10, 1999.
[Chiba00]
``Chiba City, the Argonne Scalable Cluster'', http://www.mcs.anl.gov/chiba/.
[CK01] E. Cantu-Paz and C.
Kamath, "On the use of Evolutionary Algorithms in Data Mining",
submitted as a book chapter to Data Mining: A Heuristic Approach, Eds. H.
Abbass, R. Sarker, and C. Newton. To be published in Fall 2001.
[CKN+00]
A. Choudhary, M. Kandemir, J. No, G. Memik, X. Shen, W. Liao, H. Nagesh, S.
More, V. Taylor, R. Thakur,
and R. Stevens. ``Data Management for Large-Scale Scientific Computations in
High Performance Distributed Systems'' in Cluster Computing: the Journal of
Networks, Software Tools and Applications, Volume 3, Issue 1, pp. 45-60, 2000.
[CLR+00]
P. Carns, W. Ligon, R. Ross, and R. Thakur, ``PVFS: A Parallel File System For
Linux Clusters'', Proceedings of the 4th Annual Linux Showcase and Conference,
Atlanta, GA, October 2000, pp. 317-327.
[CM95]
A. Chen and V. Markowitz, An Overview of the Object Protocol Model (OPM)
and the OPM Data Management Tools, Information
Systems, Vol. 20, No. 5, 1995.
[CTB+96]
A. Choudhary, R. Thakur, R. Bordawekar, S. More, and S. Kutipidi, ``PASSION:
Optimized I/O for Parallel Applications,'' IEEE Computer, (29) 6:
70-78, June 1996.
[DFL+96]
D. J. Downing, V. V. Fedorov, W. F. Lawkins, M. D. Morris, G. Ostrouchov, Large
datasets: segmentation, feature extraction, and compression. Technical Report ORNL/TM-13114, Oak Ridge National
Laboratory, 1996.
[DBN+96]
Dennis R.L., D.W. Byun, J.H. Novak, K.J. Galluppi, C.C. Coats, M.A. Vouk,
"The Next Generation of Integrated Air Quality Modeling: EPA's
Models-3," Atmospheric Environment, Vol 30 (12), pp 1925-1938, 1996.
[DFL+00]
D. J. Downing, V. V. Fedorov, W. F. Lawkins, M. D. Morris, G. Ostrouchov, Large
Data Series: Modeling the Usual to Identify the Unusual, Computational
Statistics and Data Analysis, 32, 245-258, 2000.
[DHB00]
S. Decker, F. van Harmelen, J. Broekstra, M. Erdmann, D. Fensel, I. Horrocks,
M. Klein, S. Melnik, The Semantic Web - on the Roles of XML and RDF .
In: IEEE Internet Computing. September/October 2000.
[DOT97]
S. Davidson, C. Overton, V. Tannen. BioKleilsi: A Digital Library for
Biomedical Researchers. Journal of
Digital Libraries. Nov. 1997
[FJP90]
J.C. French, A.K. Jones and J.L. Pflatz, Scientific Database Management
(Final Report) NSF Workshop on Scientific Database Management, Dept. of
Computer Science, Univ. of Virginia, Charlottesville, August 1990.
[FK01]
I. Foster and C. Kesselman, ``A High-Performance Data Grid Toolkit: Enabling
Technology for Wide Area Data-Intensive Applications,'' A DOE SciDAC
Middleware and Network Project, 2001.
[FLO00]
http://xsb.sourceforge.net/flora/
[FS95] U. Fayyad and P.
Smyth, "From Massive Data Sets to Science Catalogs: Applications and
Challenges", in Proceedings of the Workshop on Massive Data Sets, J.
Kettenring and D. Pregibon (eds.), 1995.
[GKP97]
G. A. Geist, J. A. Kohl, P. M. Papadopoulos, ``CUMULVS: Providing
Fault-Tolerance, Visualization and Steering of Parallel Applications,''
International Journal of High Performance Computing Applications, Volume 11,
Number 3, August 1997, pp. 224-236.
[GLM00]
A. Gupta, B. Ludäscher and M. E. Martone, Knowledge-Based
Integration of Neuroscience Data Sources,
12th Intl. Conf. on Scientific and Statistical Database Management (SSDBM) , Berlin, Germany, IEEE Computer Society, July,
2000.
[HDF99]
``HDF5 Reference Manual Release 1.2'', October 1999.
[HRC95]
M. Harry, J. del Rosario, and A. Choudhary, ``The Design of VIP-FS:
A Virtual, Parallel File System for High Performance Parallel and
Distributed Computing,'' ACM Operating Systems Review, Vol. 29, No. 3, July
1995.
[IPP99]
Ivezic N.A., Potok T.E., Pouchard L., Manufacturing Multiagent Framework for
Transitional Operations. IEEE Internet
Computing, 3 (5), 58-59, 1999.
[John99]
Theodore Johnson: Performance Measurements of Compressed Bitmap Indices. Very
Large Data Base Conference (VLDB) 1999, pp. 278-289.
[KS96]
Vipul Kashyap, Amit P. Sheth: Semantic and Schematic Similarities Between
Database Objects: A Context-Based Approach. VLDB Journal 5(4):
276-304(1996).
[KS97]
E. Keogh and P. Smyth, A probabilistic approach to fast pattern matching in
time series databases, in Proc. Third
International Conference on Knowledge Discovery and Data Mining, Newport
Beach, California, August 1997.
[LGM00]
B. Ludäscher, A. Gupta, M. E. Martone, Model-Based
Information Integration in a Neuroscience Mediator System ,
demonstration track, 26th Intl. Conference on Very Large Databases (VLDB),
Cairo, Egypt, September, 2000.
[LGM01]
B. Ludäscher, A. Gupta and M. E. Martone, Model-Based
Mediation with Domain Maps,
accepted for publication in IEEE Intl. Conf. on Data Engineering, Heidelberg, Germany, 2001.
[LPV00]
B. Ludäscher, Y. Papakonstantinou, P. Velikhov, Navigation-Driven
Evaluation of Virtual Mediated Views,
Intl. Conference on Extending Database Technology (EDBT), Konstanz, Germany, LNCS 1777, Springer, March
2000.
[LSC00]
W. Liao, X. Shen, and A. Choudhary ``Meta-Data Management System for
High-Performance Large-Scale Scientific Data Access'' in the 7th
International Conference on High Performance Computing, Bangalore, India,
December 17-20, 2000
[LSS99]
Long, J, Spencer, P, Springmeyer, R. SimTracker-using the web to track
computer simulation results. International Conference on Web-Based Modeling
and Simulation, San Francisco, CA, January 17-20, 1999
[MKS96]
E. Mena, V. Kashyap, A. Sheth, and A. Illarramendi, OBSERVER: An Approach
for Query Processing in Global Information Systems based on Interoperation
across Pre-existing Ontologies. In: 1st IFCIS Intl Conf. on Cooperative Information Systems
(CoopIS'96), pp. 14-25, Brussels, Belgium, 1996.
[MKW00]
P. Mitra, M. Kersten, G. Wiederhold. A Graph-Oriented Model for
Articulation of Ontology Interdependencies, Proceedings
of EDBT, March 2000.
[MLF00]
Todd D. Millstein,
Alon Y. Levy, Marc Friedman,
Query Containment for Data Integration Systems, PODS 2000: 67-75
[MMS+94] E. Mesrobian, R.R.
Muntz, E.C. Shek, C.R. Mechoso, J.D. Farrara, and P. Stolorz, "QUEST:
Content-based Access to Geophysical Databases", AAAI Workshop on AI
Technologies in Environmental Applications, Seattle, WA, Jul-Aug 1994.
[MPI97]
Message Passing Interface Forum, ``MPI-2: Extensions to the Message-Passing
Interface'', http://www.mpi-forum.org/docs/docs.html, July 1997.
[namesys01]
namesys.com, ``Reiser file system'', http://www.reiserfs.com/.
[NKP+96]
N. Nieuwejaar, D. Kotz, A. Purakayastha, C.
Ellis, and M. Best, ``File-Access Characteristics of Parallel
Scientific Workloads'', in IEEE Transactions on Parallel and Distributed
Systems, volume 7, number 10, pp. 1075-1089, October 1996.
[Olke83]
F. Olken, HOPT: A Myopic Version of the STOCHOPT Automatic File Migration
Policy, Proceedings of the 1983 ACM SIGMETRICS Conference on Measurement and
Modeling of Computer Systems, pp: 39-43.
[OSH01] Clustering High
Dimensional Massive Scientific Databases, Ekow J. Otoo, Arie Shoshani, Seung-Won
Hwang, submitted for publication, 2001.
[PBB+00]
K. Preslan, A. Barry, J. Brassow, R. Cattlelan, A. Manthei, E. Nygaard, S. Van
Oort, D. Teigland, M. Tilstra, M. O'Keefe, G. Erickson, and M.
Agarwal, ``A 64-bit, Shared Disk File System for Linux'', Proceedings
of the Eighth NASA Goddard Conference on Mass Storage Systems and
Technologies, March 2000.
[PDO00]
W. M. Putman, J. B. Drake, and G. Ostrouchov, Statistical Downscaling of
the United States Regional Climate from Transient GCM Scenarios, in Proc. 15th Conference on Probability
and Statistics in the Atmospheric Sciences, American Meteorological
Society, p. J8-J11, 2000.
[PEI99]
Potok T.E., Elmore M.T., and Ivezic N.A.,Collaborative Management
Environment Proceedings of the InForum99 Conference, http://www.doe.gov/inforum99/proceed.html,
1999.
[PIS01]
Potok, T.E., Ivezic N.A, and Samatova, N.F., Agent-based architecture for
flexible lean cell design, analysis, and evaluation, Proceedings of the 4th Design of Information Infrastructure Systems for
Manufacturing Conference, 2001.
[PTB+00]
J.P. Prost, R. Treumann, R. Blackmore, C. Harman, R. Hedges, B.
Jia, A. Koniges, A. White,
``Towards a High-Performance and Robust Implementation of MPI-IO on top of
GPFS'', LLNL Internal report UCRL-JC-137128, 2000.
[PTS+01]
Potok T.E., Treadwell J.N., Samatova, N.F., Elmore M.T., and Reed J.W. VIPAR
- Virtual Information Processing Agent Research Final Report, available by
request, 2001.
[RFG+00]
A. Roy, I. Foster, W. Gropp, N. Karonis, V. Sander, and B. Toonen, ``MPICH-GQ:
Quality of Service for Message Passing Programs'', in Proc. of SC2000, 2000.
[SBN+99]
A. Shoshani, L. M. Bernardo, H. Nordberg, D. Rotem, and A. Sim, Storage
Management Techniques for Very Large Multidimensional Datasets, Eleventh
International Conference on Scientific and Statistical Database Management (SSDBM
1999).
[SOG+01]
N. F. Samatova, G. Ostrouchov, A. Geist, A. Melechko, RACHET: A New
Algorithm for Clustering Multi-dimensional Distributed Datasets, in Proc. The Third Workshop on Mining Scientific Datasets, Chicago, April,
2001.
[STACS]
The Storage Access Coordination System, http://gizmo.lbl.gov/stacs.
Includes references to several papers.
[TGL96]
R. Thakur, W. Gropp, and E. Lusk, ``An Abstract-Device Interface for
Implementing Portable Parallel-I/O Interfaces ,'' in Proc. Of the 6th
Symposium on the Frontiers of Massively Parallel Computation, October 1996,
pp. 180-187.
[TGL98]
Rajeev Thakur, William Gropp, and Ewing Lusk, ``A Case for Using MPI's Derived
Datatypes to Improve I/O Performance,'' in Proc. of SC98: High Performance
Networking and Computing, November 1998.
[TLG97]
R. Thakur, E. Lusk, and W. Gropp, ``Users Guide for ROMIO: A High-Performance,
Portable MPI-IO Implementation,'' Technical Memorandum ANL/MCS-TM-234,
Mathematics and Computer Science Division, Argonne National Laboratory,
October 1997.
[WI93]
J.L. Wiener and Y.E. Ioannidis, ``A Moose and a Fox Can Aid Scientists with
Data Management Problems,'' Proc. 4th
Int'l Workshop on Database Programming Languages, New York, Aug. 1993.
Back
to the table of contents
Appendix
- A: Table
of Acronyms
ACPI
Accelerated Climate Prediction Initiative
ADIO
Abstract-Device Interface for I/O
AIX
Advanced Interactive eXecutive
AMIP
Atmospheric Model Intercomparison Project
ANL
Argonne National Laboratory
API
Application Program Interface
ASPECT
Adaptable Simulation Product Exploration via Clustering Toolkit
ATM
Asynchronous Transfer Mode
BABAR
B/B-bar system of mesons
BNL
Brookhaven National Laboratory
CFD
Computational Fluid Dynamics
CMIP
Coupled Model Intercomparison Project
CORBA
Common Object Request Broker Architecture
CPU
Central Processor Unit
CTS
Climate Time Series
CUMULVS
Collaborative User Migration, User Library for Visualization and
Steering
DNA
Deoxyribo Nucleic Acid
DOE
Department of Energy
DOM
Document Object Model
EPA
Environmental Protection Agency
ETC
Enabling Technology Center
FTP
File Transfer Protocol
GB
Gigabyte
GFS
Global File System
GRA
Graduate Research Assistant
GSN
Gigabyte System Network
GT
Georgia Institute of Technology
HARNESS
Heterogeneous Adaptable Reconfigurable
NEtwork SystemS
HDF
Hierarchical Data Format
HEP
High Energy Physics
HENP
High Energy Nuclear Physics
HOPT
Hazard OPTimal algorithm
HP
Hewlett Packard
HPSS
High Performance Storage System
HRM
Hierarchical Resource Manager
HSI
Hierarchical Storage Interface
HTML
HyperText Markup Language
ICA
Independent Component Analysis
IEEE
Institute of Electrical and Electronics Engineers
I/O
Input/Output
IP
Internet Protocol
LAN
Local-Area Network
LBNL
Lawrence Berkeley National Laboratory
LDRD
Laboratory Directed Research and Development
LLNL
Lawrence Livermore National Laboratory
LFU
Least Frequently Used
LRU
Least Recently Used
LRU-K
Least Recently Used based on last K references
MB
Megabyte
MCNC
Microelectronics Center of North Carolina
MICS
Mathematical, Information, and Computational Sciences
MPI
Message Passing Interface
MPI-IO
Message Passing Interface Input/Output
MPICH
ANL implementation of MPI
MPICH-GQ
ANL implementation of MPI with Globus and quality-of-service support
NC
North Carolina
NCSU
North Carolina State University
NCAR
National Center for Atmospheric Research
NERSC
National Energy Research Scientific Computing Center
NWU
Northwestern University
ORB
Object Request Broker
ORMAC
Oak Ridge Mobile Agent Community
ORNL
Oak Ridge National Laboratory
PASSION
Parallel And Scalable Software for Input-Output
PBIO
Portable Binary Input/Output (from Georgia Tech)
PC
Personal Computer
PCA
Principal Component Analysis
PCI-X
Peripheral Component Interconnect - eXtended
PCMDI
Program for Climate Model Diagnosis and Intercomparison
PDB
Protein Structure Database
PI
Principal Investigator
POSIX
Portable Operating System Interface
PPDG
Particle Physics Data Grid
PVFS
Parallel Virtual File System
QOS
Quality of Service
RACHET
Recursive Agglomeration of Clustering Hierarchies by Encircling Tactic
RAIT
Redundant Array of Independent Tapes
ROMIO
ANL implementation of MPI-IO
SGI
Silicon Graphics Incorporated
SciDAC
Scientific Discovery through Advanced Computing
SDLIP
Simplified Digital Library Interoperability Protocol
SDM
Scientific Data Management
SDSC
San Diego Supercomputing Center
SQL
Structured Query Language
SRB
Storage Resource Broker
SLAC
Stanford Linear Accelerator
ST
Scheduled Transfer
STACS
Storage Access Coordination System
STAR
Solenoidal Tracker at RHIC (Relativistic Heavy Ion Collider)
STOCHOPT
STOChastic OPTimal algorithm
SWISS-PROT Protein
database at the Swiss Institute of Bioinformatics
TB
Terabyte
TCP/IP
Transfer Control Protocol/Internet Protocol
UC
University of California
UCSD
University of California San Diego
UDP
User Datagram Protocol
VIPAR
Virtual Information Processing Agent Research
VIP-FS
Virtual Parallel File Systems Project
WAN
Wide-Area Network
XEWA
XML Enambles Wide-area Access workshop
XML
eXtensible Markup Language
XWrap
name of a software program, not an acronym