
SDM
People
Publications
Projects
Investigators: John Wu, Suren Byna, Bin Dong
Parallel sorting is an essential tool for scientific data management, but existing algorithms in several large-scale distributed data analytic systems are ineffective with skewed data, where there are many duplicate values.
We designed and developed novel, skew-aware, and highly-scalable parallel sorting.
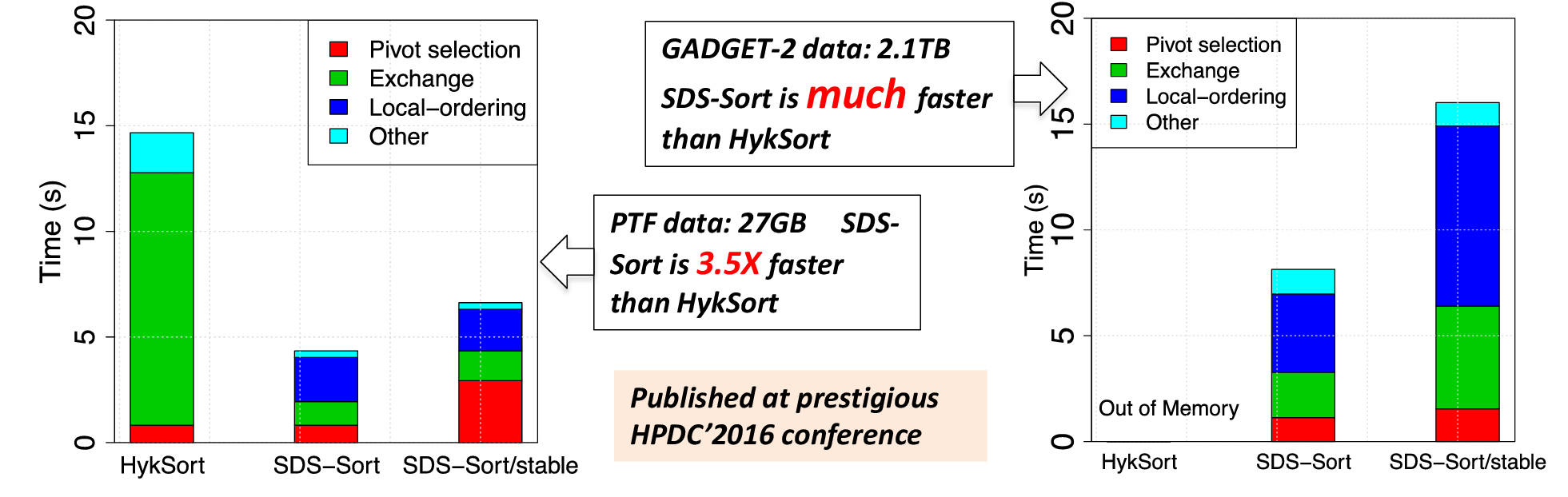
HykSort is the fastest known parallel sorting algorithm, but when the sorting key is skewed, it could have a very significant load imbalance that causes it to run out of memory on some nodes. In contrast, SDS-Sort can maintain a good load balance (theoretically bounded by O(4N/p)) and reduce the execution time. SDS-Sort also provides stable sorting.
A more efficient sorting algorithm in the Scientific Data Services (SDS) framework
Cosmology datasets from a simulation (GADGET-2) and from an observation (Palomar Transient Factory-PTF)