
Scientific Data Management Framework Workshop
August 25, 2003
Background
Scientific Data management technology involves specialized areas of expertise, such as data mining techniques, storage efficient access, indexing, etc. One cannot expect a scientist to learn the use of these technologies and their interfaces and somehow put them together for his/her specialized needs. The key to delivering such technology is to simplify the tasks that the application scientist has to perform in order to take advantage of the data management technology. There are three principles that can simplify the process: 1) abstraction of the functionality; 2) interoperation of components; and 3) automation of optimized data structures.
1. Abstraction of the functionality
The functionality of a data management component should only describe "what the component does", not how it does that. For example, an index should be exposed in terms of the search expression that is applied to it, not in terms of functions applied to the data structures that implement the index. Another aspect of functionality abstraction is that the components should be of general use, not tailored to a specific application. As a result of this approach user interfaces and function invocation are simple to understand and use. This principle has proven to be very effective with existing commercial data management products, where the concepts of a logical data model (the abstract data structure and query language exposed to the user) is used. The physical data structures and indexes that implement this model are not exposed. The same principle is valuable for scientific applications dealing with large volumes of data that need to be efficiently stores, and effectively searched.
2. Interoperation of components
Consider a simulation that generates data in a particular format, such as HDF5 or NetCDF. If the next step requires that the dataset will be indexed for an efficient search, then it is necessary that the index generator can read (digest) that format. Similarly, suppose that the scientist wishes to apply a parallel cluster analysis to the dataset. Here again, the cluster analysis component should be able to read the specific format. How does one deal with various formats used by different scientific domains? This is a challenge that needs to be addressed as part of simplifying the application scientist's task. This task of making components interoperable cannot be left to each individual scientist to perform for his/her application. The principle to adhere to is that components made available as part of the data management "toolkit" need to interoperate, or efficient data format translators have to be provided.
3. Automation of optimized data structures
It is well known in the scientific domains as well as in the data management community that the way the data is stored and indexed determines to a large extent the ability to search and access the data efficiently. The term used for the way the data is accessed is referred to as "access patterns". Thus, the challenge is one of matching the physical data storage layout and indexes to the anticipated access patterns. The most effective approach is to get access pattern "hints" from the user at the time the data is generated. Such hints can be used to determine how to store the data, such as the granularity and algorithm for striping data on disks. Components should be designed to automatically take advantage of such hints, without exposing to the user the details of how the data structures were affected. Another aspect of automatic optimization of data structures and indexes is the ability to infer access patterns. In many cases, access pattern hints are not known ahead of time or may change over time. The principle that helps simplifying the scientist's task in using data management technology is that the data structures should be optimized automatically according to observed access patterns. As an example, a very effective technique for minimizing expensive access of data from robotic tape systems is to have a large disk cache that is designed to keep data that is frequently used in the cache. Similar techniques are used to pre-fetch or replicate data to locations that are most likely to use them. Other techniques are designed to reorganize the data periodically according to access patterns.
The Framework
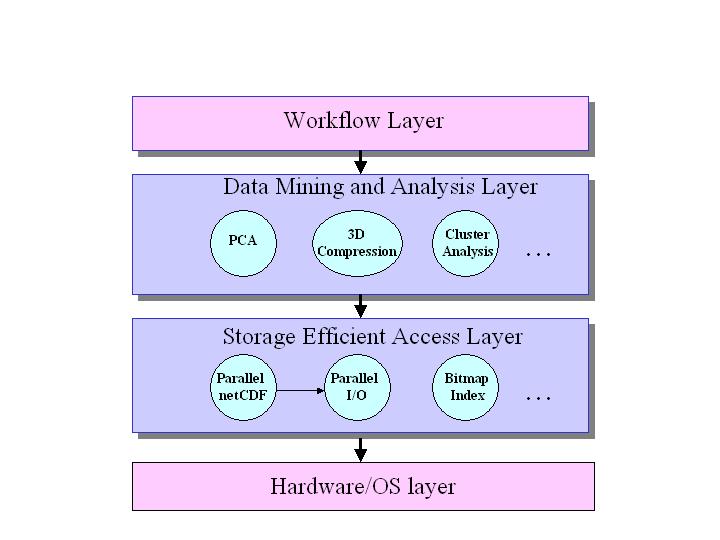
In order to achieve the above goals it is necessary to have a framework that permits the interoperation of the SDM components. We distinguish between two types of components: Data Mining and Analysis (DMA) components, and Storage Efficient Access (SEA) components. The DMA components includes tools for compressing or summarizing data sets, tools for finding patterns in the data, such as principle component analysis (PCA) or cluster analysis, and tools for performing statistical analysis. The SEA components are designed to provide efficient access and search capabilities. They include components that provide parallel I/O to a computation cluster, specialized data format layers that are build on top of parallel I/O, such as parallel netCDF, indexing methods for efficient data search, and tools that can access mass storage systems efficiently.
In addition, we see the need for tools that provide support of Scientific Workflows. Scientific workflows are different from "business workflows" in that they have to be designed to deal with large amounts of input/output data, as well as streaming data between components. For example, suppose that one step of the workflow is to run a climate simulation that produces a terabyte of data. The second step is to summarize the data, and the third is to apply PCA analysis on the data. While the "conceptual workflow" is quite simple, the "executable workflow" must include the allocation of space for the data generated by the simulation, the invocation of parallel I/O technology, the streaming of data from the simulation step to the summarization step, etc. In addition, the executable workflow had to deal with format incompatibility if necessary. For example, if the output of the summarization step is not in a format readable by the PCA step, the translation software needs to be invoked. Overall, scientific workflows are more data-flow oriented, whereas business workflows are more control-flow oriented (e.g., they often require require the coordination of a number of small message and document exchanges). Consequently, the business workflow systems are not adequate for the data-intensive analysis "pipelines" found in scientific applications.
The above framework is quite demanding in terms of the kind of components that
the framework should include and the way they interoperate. In this workshop
we plan to explore the interoperation and workflow technology that currently
exists, and perhaps identify what technology needs to be developed in order
to support this framework vision. The figure below shows the relationship of
these technologies as layers that build upon each other.
The structure of the workshop
The workshop will have two parts: 1) in the morning we'll have a series of short presentations (or position statement) by several members of the SDM Center, and invitees. 2) In the afternoon, we'll have round table discussions on a list of topics including:
A report summarizing the discussions/recommendations of the workshop will be generated.
Agenda:
Scientific Data Management Framework Workshop
August 25, 2003
Building 221, Conference Room A216.
8:00 Continenetal breakfast (provided)
8:30 - 9:30 SDM center infrastructure: plans and examples
(15 Minutes each)
· The Integrated Data Management and Analysis Framework (IDMAF) - architectural considerations, Arie Shoshani, LBNL
· Multi-level infrastructure to support parallel netCDF (Storage Efficient Access layer), Rob Ross, ANL / Alok Choudhary, NWU
· A data exploration environment (Data Mining and Analysis layer), Nagiza Samatova, ORNL
· A workflow design and execution tool (Scientific Process Automation layer), Mladen Vouk, NCSU
9:30 - 10:30 Scientific applications: data needs and experience
(15 Minutes each)
· Data diversity issues in the Science Environment for Ecological Knowledge (SEEK) project, Matt Jones, UCSB
· Issues of data management, storage, and bandwidth for FLASH astrophysics applications, Andrew Siegel, U of Chicago
· Data management requirements for Remote and Distributed Visualization, John Shalf, LBNL
· Data issues in TOPS: the Terascale Optimal PDE Simulation center, Bill Gropp, ANL
10:30 - 11:00 Coffee Break (provided)
11:00 - 12:30 Technology solutions: current state of the art
(15 Minutes each)
· The Common Component Architecture approach to workflow management and component interoperability, Dennis Gannon, Indiana University
· SCIRun: Data flow and computational steering of large scale computer simulations, Steve Parker, U of Utah
· Taming Heterogeneity - the Ptolemy Approach, Steve Neuendorffer, UCB
· Data planning and virtual-data flow execution for grid applications, Ian Foster, ANL
· Data placement and data streaming - essential features of scientific workflow execution, Miron Livny, U of Wisconsin
12:30 - 1:30 Lunch Break (ANL Cafeteria)
1:30 - 3:30 Round table discussions (part 1)
· Is the 3-layer architecture appropriate/sufficient?
· How should the components interoperate?
· What functionality should a workflow engine have?
· How to deal with large volumes of data? Space allocation issues?
· How to provide a "data streaming model" of running a workflow?
3:30 - 4:00 Coffee Break (provided)
4:00 - 5:30 Round table discussions (part 2)
· How to deal with data format transformations?
· How useful are Web Service technologies? Do they introduce inefficiencies?
· How to package this set of diverse technologies?
· What is the user/scientist exposed to?
· What tools should we aspire to have in the SDM toolkit?
· Are we missing some fundamental tools/technologies?
7:00 - 9:00 Working dinner (hosted)
· Additional issues/topics not discussed in the workshop (but should
have)
· If we hold another workshop, what should the focus be on?
Location: Giordano's of Willowbrook
641 Plainfield Road, Willowbrook, IL
630/325-6710
Logistics
The workshop will take place at Argonne National Laboratory. If you wish you can stay at the hotel on the lab's premises, called the Guest House. Please call them directly for reservations as soon as you can to insure you have get a room. For additional logistic information and registration form (by invitation only) please click here. Note: it is important that you register as soon as you can to help planning and preparation of gate passes.